作者:赵泽鑫|QE_LAB
Selenium 自动化测试如何优雅的解决图片验证码问题
说到自动化测试那一定避不开登陆注册页面,而大多数情况下这两个简单的页面都存在一个小困难就是验证码,以前我的解决办法都是在测试环境粗暴的写死一个万能验证码,或者给程序一个10秒钟的线程阻塞,手动输入验证码以跳过这个步骤。这样就可以不那么优雅的实现的登陆注册自动化测试啦。但是思来想去,既然是自动化测试,那就不应该有手动或者写死代码的魔改方式存在,而是全自动的测试。于是展开一番探索后的我找到了两种方法解决这个问题。
一、cookie方式绕过验证
首先手动登陆一下,然后抓包找到对应的cookie值,复制该值找到和登陆相关的key:value并使用selenium的add_cookie 方法,使用cookie后刷新页面即可跳过登陆验证直接进入系统。或者使用request库中的get_url方法,传入cookie值也可以达到同样的目的。但这样的做法并无法完成对登陆页面的测试,同时当cookie失效或者每次登陆的值都有变化的时候比较恼火,于是就有了第二种方法。
二、图像识别将图片转化为字符串
这两种方法的本质是相同的,都是使用AI的方式,自动识别验证码,完成填入。只不过采用了不同的包和方法完成的。在这儿之前我们先想一下完成验证码的提取应该有哪些步骤?
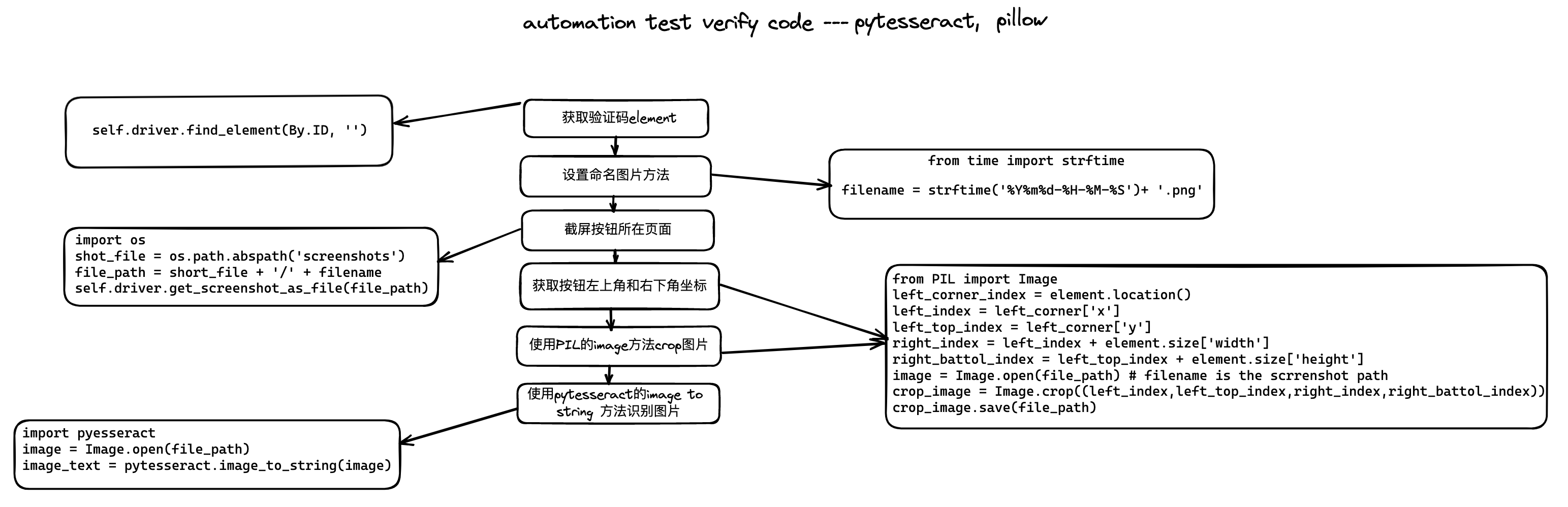
- 进入登陆页面并截屏
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.LoginPage.com')
driver.save_screenshot(file_name)
- 保存图片至文件夹
一般情况下,我们的项目路径下都会建立一个保存屏幕截图的文件夹,用来保存出现错误后的图片文件,通常使用当时的时间作为文件的名称。
import os
from time import strftime
file_name = strftime('%Y%m%d-%H-%M-%S') + '.png'
file_path = os.path.abspath('ScreenShot') + '/' + file_name
driver.get_screenshot_as_file(file_path)
- 截图出验证码部分的图片
这里说明一下,我们需要element的左上角坐标和右下角坐标就能完成对验证码部分的截图。element的location方法本质上是使用了getElementRect(),区别是其只返回了x,y坐标而没有width和height的值。
from selenium import webdriver
from selenium.webdriver.common.by import By
from PIL import Image
driver = webdriver.Chrome()
element = driver.find_element(By.ID, 'xxxx')
left_top_corner_index = element.location()
left_top_x = left_top_corner_index['x']
left_top_y = left_top_corner_index['y']
right_down_x = left_top_x + element.size['width']
right_down_y = left_top_y + element.size['height']
image = Image.open(screenshot_image)
crop_image = Image.crop((left_top_x, left_top_y, right_down_x, right_down_y))
crop_image.save(file_path)
- 将验证码部分的图片中的文字转化为字符串打印出来
import pytesseract
image = Image.open(verify_code_image)
verify_code_text = pytesseract.image_to_string(image)
pytesseract的AI识别能力较差,只能识别一些简单的验证码,如下图:
这种验证码没有太多的额外干扰,但是当遇到干扰线很多甚至动来动去的那种就寄了,所以我们就要找其他能够准确识别的第三方库来完成这件事。
import DdddOcr
def convert_to_string():
ocr = DdddOcr()
with open(r'file_path', 'rb') as f:
img_bytes = f.read()
res = ocr.classification(img_bytes)
return res
这是一个开源的验证码识别工具,测试下来准确度还说的过去,还可以写一个重试的机制,防止一次识别错误导致登陆失败,可以多尝试一下。接下来就可以愉快进行自动化的登陆啦。
三、讨论:自动化测试要不要包含验证码登陆?
这个问题我有跟其他同事简单的讨论过,一种观点是当AI库的识别能力可以达到一个较高的准确程度的前提下,自动化测试就应该包含验证码登陆,毕竟E2E测试就是应该更加贴近真实的用户操作。另外一种观点是在E2E阶段增加验证码这种不稳定的case在测试中会徒增不必要的麻烦,应该在接口测试和单元测试进行,E2E测试中只需要使用万能验证码或者其他方式跳过验证码的步骤进行登陆测试就可以了。欢迎大家发表自己的观点和看法!

