批量制造数据的方法有很多种,也有许多专业的工具,但是都算不上高效,针对MySQL的批量插入数据,目前认为最高效的方式是通过执行JAVA代码(通过设置事务为非自动提交,以executeBatch批处理提交大量插入事务)来实现,但是JAVA的灵活参数化和大用户量分布式并发执行,绝对没有LoadRunner方便。
所以我们可以利用LoadRunner+JAVA的方式,来实现高效、高可靠、持续性的批量造数据,既利用LoadRunner的Java_Vuser:
1、在loadrunner中新建脚本(本文以LoadRunner11为例),要求选择协议类型为Java->Java Vuser
2、在Run-time Settings设置JDK路径,由于LoadRunner11不支持jdk1.8,所以推荐引用jdk1.6
3、需要mysql的java驱动,可以到MySQL官网下载"mysql-connector-Java",并通过Run-time Settings引用JAR包
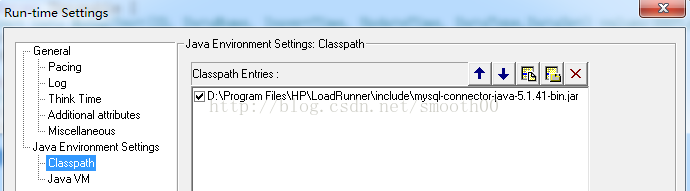
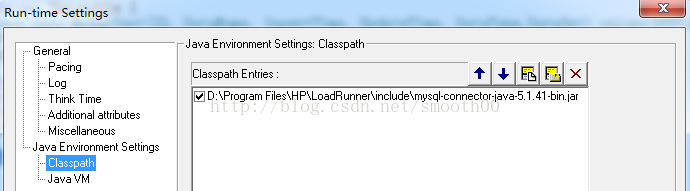
4、在Java Vuser输入以下样例代码:
/*
* LoadRunner Java script. (Build: _build_number_)
*
* Script Description:
*
*/
import lrapi.lr;
import java.beans.Statement;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class Actions
{
private Connection conn = null;
PreparedStatement statement = null;
// connect to MySQL
void connSQL() {
String url = "jdbc:mysql://172.16.1.67:3306/test?characterEncoding=UTF-8";
String username = "root";
String password = "123456"; // 加载驱动程序以连接数据库
try {
Class.forName("com.mysql.jdbc.Driver" );
conn = DriverManager.getConnection( url,username, password );
}
//捕获加载驱动程序异常
catch ( ClassNotFoundException cnfex ) {
System.err.println(
"装载 JDBC/ODBC 驱动程序失败。" );
cnfex.printStackTrace();
}
//捕获连接数据库异常
catch ( SQLException sqlex ) {
System.err.println( "无法连接数据库" );
sqlex.printStackTrace();
}
}
// disconnect to MySQL
void deconnSQL() {
try {
if (conn != null)
conn.close();
} catch (Exception e) {
System.out.println("关闭数据库问题 :");
e.printStackTrace();
}
}
public int init() throws Throwable { connSQL(); return 0; }//end of init
public int action() throws Throwable { String sql = "insert into MySqlTest(ID, DataName, InsertTime, UpdateTime, DataType,DataSet) values(REPLACE(uuid(), '-', ''),?,now(),null,1,'LoadRunner')";
conn.setAutoCommit(false); statement = conn.prepareStatement(sql,ResultSet.TYPE_SCROLL_SENSITIVE,ResultSet.CONCUR_READ_ONLY);
lr.start_transaction("Insert"); for(int i=0;i<1000;i++){//每1000条记录为一组事务,每个虚拟用户至少执行一组批量插入事务
statement.setString(1,"Test-A2B-<RadParam>");//用LoadRunner的方式设置随机数参数
statement.addBatch(); } statement.executeBatch();
conn.commit();
lr.end_transaction("Insert", lr.AUTO); return 0; }//end of action
public int end() throws Throwable { deconnSQL(); return 0; }//end of end
}
5、将以上脚本放到Loadrunner中执行(场景设置100用户,每个用户只执行一次,同时执行,这样就确保只插入10万条记录),经过测试,发现最多16秒就完成10万条记录的插入(平均执行的时间是11.658秒)。
7、也可以将for循环去掉,通过loadrunner的action循环1000次来实现
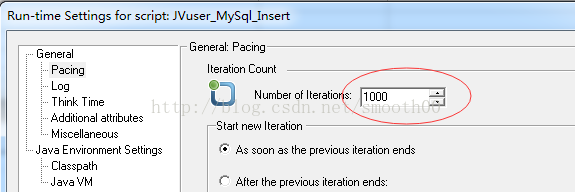
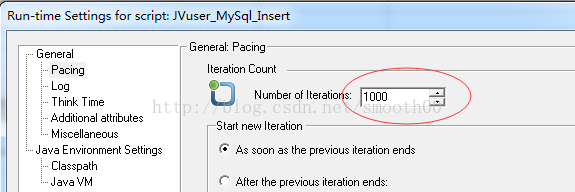
但是这样改变后速度要比用for循环慢多了,经过测试发现插入10万条数据,需要33秒(平均执行一次action是0.027秒),为什么呢,仔细对照就发现是因为action里包括了conn.commit(),也就是说每次循环都执行事务提交,批量1000条插入变成了单条插入。把脚本改动一下:
public int init() throws Throwable {
connSQL();
String sql = "insert into MySqlTest(ID, DataName, InsertTime, UpdateTime, DataType,DataSet) values(REPLACE(uuid(), '-', ''),?,now(),null,1,'LoadRunner')";
conn.setAutoCommit(false);
statement = conn.prepareStatement(sql,ResultSet.TYPE_SCROLL_SENSITIVE,ResultSet.CONCUR_READ_ONLY);
return 0;
}//end of init
public int action() throws Throwable {
lr.start_transaction("action");
statement.setString(1,"Test-A2B-<RadParam>");
statement.addBatch();
lr.end_transaction("action", lr.AUTO);
return 0;
}//end of action
public int end() throws Throwable {
statement.executeBatch();
conn.commit();
deconnSQL();
return 0;
}//end of end
这么一改动,就把prepareStatement和commit都放到循环action之外,相当于一个用户执行完1000条预插入记录后,才进行commit提交,速度立马提高,经过测试,10万条记录批量insert只要15秒(平均执行一次action是0.001秒)。
8、如果要插入更多的数据,只需要用更多的用户和执行更长的并发时间就能轻松实现,而且参数化方便,如果单台压力机承受不了,还可以分布式部署多台压力机。
注:以上是批量插入数据的脚本,有人会将批量更新也放到脚本中执行,这时候就要避免行级锁在高并发时引起死锁,所以强调更新条件应该使用主键。

