作者:安欣阳 | QE_LAB
最近在项目上使用到了cucumber这个工具,第一次知道自动化测试还能用BDD(Behavior Driven Development)的形式来写,感觉很有意思同时也体会到了不少好处,所以想和大家分享一些学习过程和心得。
一. 简述
Cucumber是一个支持BDD(behavior driven development)的工具,它允许我们使用一种叫Gherkin的语言定义的简单语法, 用自然语言来描述用户故事。Cucumber本身是Ruby编写的,但它可以用来测试用其他语言编写的代码,比如java,c#,python等。Gherkin是一组语法规则,用于编写可读性强的自然语言测试用例,这是一种业务人员可读懂的,特定领域的语言,它可以让你描述软件的行为,而不用详细说明如何实现这个行为。Gherkin语言其实可以使用不同国家语言的单词和语法书写,但相对来说英语通用性比较强,所以我们这里还是用英语举例。下面是Gherkin的一些关键词:Scenario、**Background 、Steps(包括Given、When、Then)Example**:下面是一个登录功能的scenario例子:可以看到这个scenario包括前置条件,执行步骤以及预期结果验证。一般来说,每一个执行步骤(When)都要对应一个预期结果验证(Then),来保证测试的有效性。

描述完测试场景之后,cucumber并不知道如何执行feature中的step,这就需要一个中间步骤-step定义文件。
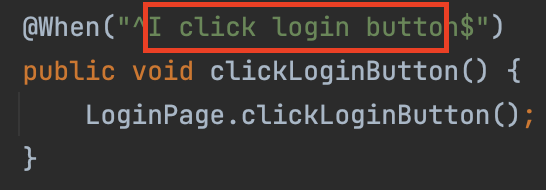
Cucumber在执行feature中的step时,通过 Gherkin 语法上的描述,自动找到与注解 value 值匹配的 Java 方法,将Gherkin steps和programming code映射起来。
编写scenario的原则 - brief
很多时候在写代码时逻辑并不难,但是给函数、变量起名字真是想破了脑袋。同样在设计并描述测试scenario的时候,QA会花很多时间来想到底应该怎么描述,下面就是一组很实用的编写原则,我在之前的项目经验中就按照这种基本原则来高效清晰地编写。
- B - Business language - Scenario中应该使用业务人员能够理解的词语
- R - Real data - Scenario中应该使用具体、真实的数据
- I - Intention revealing - Scenario中应该描述清楚意图
- E - Essential - Scenario中应该只保留重要的步骤,不直接促成结果的场景都应该被删除
- F - Focus - Scenario应该只专注于单一职责
scenario的step描述不要重复
在实际应用过程中,比较大的项目有可能是好几个国家的app都写在同一个project里面,就会有很多类似但又不完全一样的step,如果你定义了两个描述一样的step,由于cucumber在执行测试中是全局搜索step的,就会报错说不知道你想执行的是哪一个,所以最好加一些修饰语来区别。
二.为什么要使用Cucumber?
为什么要使用cucumber其实也是在问为什么要使用BDD这种模式。相对来说,使用cucumber来编写自动化测试会多付出一些effort在描述behavior和定义step上面,有的朋友可能会觉得这种额外一层的映射关系,还需要通过表达式匹配步骤文本有种脱裤子放屁的感觉。事实上,用简单英语来写测试本身意义并不大,它的特点是有助于沟通,带来的好处也是显而易见的。
- Cucumber的特点就是它侧重于验收测试,给出直接的这种behavior,也有助于dev更好的理解功能并保证开发的功能符合业务需求。
- 使用Gherkin来描述user story,能够让团队中不同的角色(Dev,QA,BA,PO等)不论是技术人员还是非技术人员都更容易读写测试,让团队能够更好的参与进来。比如可以让PO或者BA来review这些scenario看看是否cover完全或者流程符合期待,甚至可以让他们通过简单的规范学习,直接来编写这些scenario的step,后续QA或者Dev再根据编写好的scenario来写具体的function。
- 查了下其实支持BDD的工具还蛮多的,例如Behave、JBehave、Cypress等,但很多都是只支持单一编程语言的工具,这可能也是cucumber相对“火”的原因
在项目中我自己使用的过程中,很明显能感觉到使用这种BDD的写法,让所有的scenario和步骤都清晰明了(个人感受),每个case直观上看只是一些业务语句,能快速上手并理解和定位问题。下面是交互的一个过程,可以看出,相比于传统链条式的沟通模式,BDD这种方式能够让团队的每个角色成员参与进来。(但是在实际项目中,这种全员参与的模式还是比较难实现的,但是作为QA,我们可以尽可能覆盖BA编写的AC并推动PO去review自动化测试的scenario)

(图片来自 BDD in action)
三.DDT(Data Driven Test)
DDT是一种自动化测试方法,旨在测试同一个测试用例的多组输入数据,来验证应用程序在不同数据情况下的行为。在实际应用过程中,我们所需要的测试数据肯定少不了,那么cucumber是怎么实现数据传递的呢?
Keywords
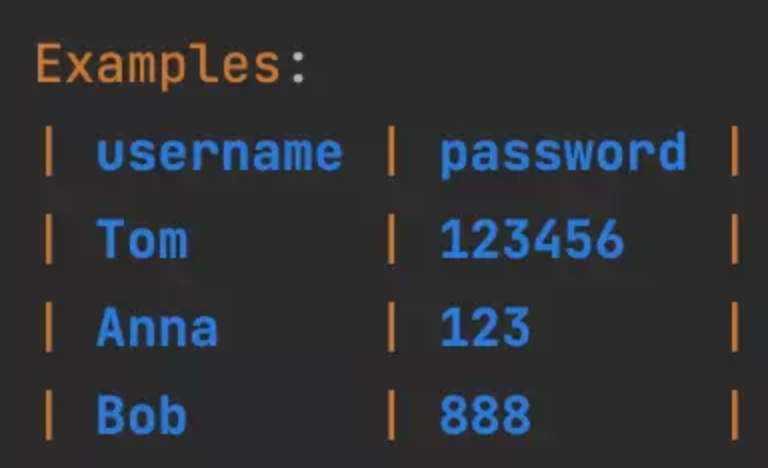
Cucumber允许使用关键字来传递参数到测试步骤中。

并在测试步骤中定义如何处理这些参数,这里使用一个正则表达式作为占位符来匹配step中的参数。比如这里将step的”Tom”和”123456”的值传递给name和password,传进function中,再调用enterLoginInfo这个方法的时候就可以使用传进来的两个参数了。

Scenario outline
Cucumber还提供一个叫做Scenario outline的特性,用于创建参数化的场景,它通常与Examples表格结合使用。
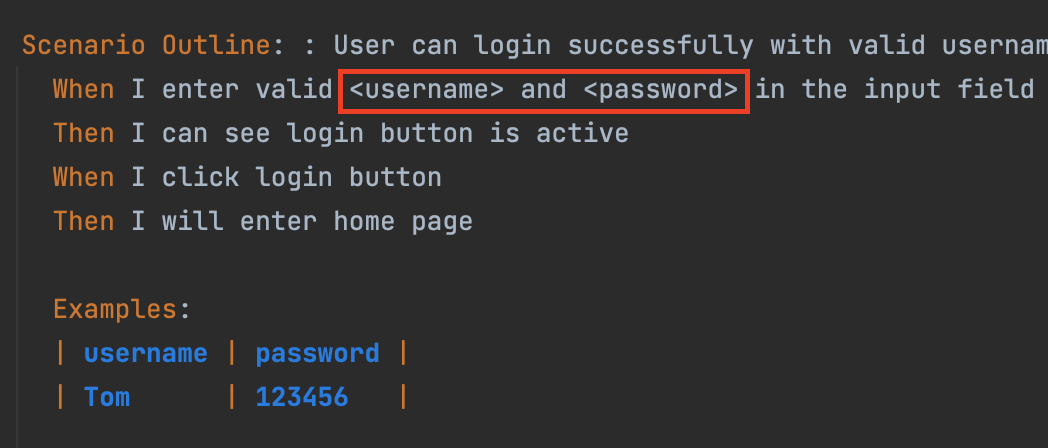
除此之外,它还允许定义一组相似的测试场景,并用不同的参数多次运行这些场景。在上一个项目中,我经常使用这样的方式,因为银行核心的一些转账流程,不管是给自己转账、给他人转账还是给信用卡还款等,基本的流程都是一致的,所以有些通用的scenario就会通过这样的参数化来快速实现,大大提高了测试效率和可读性。
External files - excel/json/xml
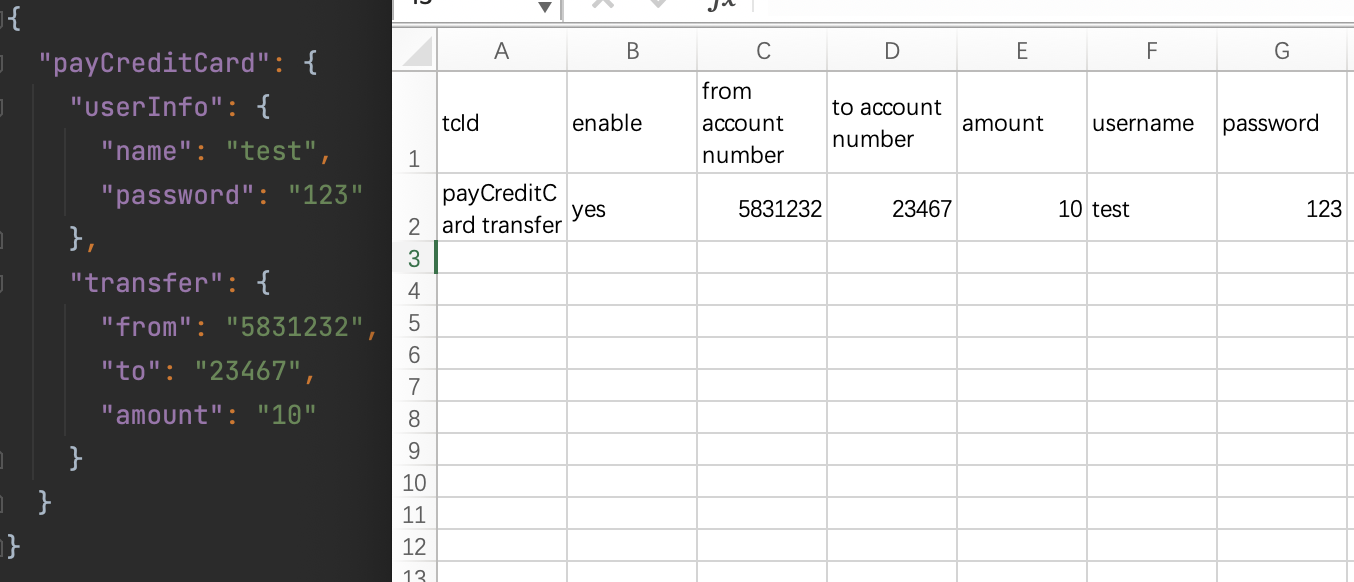
上面的传递参数的方式都是在测试文件中列出测试数据,除此之外,我们也可以将测试数据统一管理起来,写在一个excel表格或者json文件中,在代码中读取这些data file里的数据以供后续使用。这种方式对于大型项目来说尤其推荐,比如我上一个项目是一个银行相关的项目,我所在的组负责一些银行转账的核心业务,那么一个测试场景的测试数据就包括账号、转出账户、转入账户、转账金额、设置转账时间等,一个测试场景的数据就很多,更别说还有很多个测试场景,如果使用上述的一些数据传输方式,不仅会使feature文件变得冗余,同时也会导致测试数据可维护性变差。而在这种场景下,使用表格来list测试数据,就会非常清晰明了易于管理了(我们也曾经用json文件统一管理数据,但是由于数据量太大而且涉及到多人协作,会导致很多冗余的数据还不敢随意删除,并且看上去也不是很直观,每次修改数据先要关键字查找出来对应的地方)。下面是对于json&excel的一组数据的对比,可以看到右边excel形式一目了然,如果数据量非常大并且是一系列数据的话,很适合用右边的方式来管理测试数据。
四.其他在自动化测试中较好的实践
Page Object & Page Factory
Page Object已经是一种老生常谈的模式了,相信接触过自动化测试的朋友肯定都了解它,在这种模型下,应用程序的每个页面,有一个对应的页面类,此类标识该网页的WebElement,并且包含了对这些web Element执行操作的page方法,从而减少代码重复,提高测试的可维护性、可读性。因为经验比较有限,Page Factory是我在最近的项目中才了解到的,它是在POM(Page Object Model)概念中创建对象存储库的一种优化方法,它的主要目的是创建测试对象的抽象过程,并且根据需要动态地创建不同类型的测试对象(不会暴露创建逻辑,而是通过一个共同的接口来指向新创建的对象)。比如它可以将页面元素抽象成对象,使用@FindBy注解,下面是一个使用和不实用page factory的简单例子,可以看到page factory将页面元素的获取和业务操作分离开来,提高了可读性、可维护性。

之前的项目是一个大型且复杂的银行App,我们有非常多个国家的app(近十个国家),并且所有国家共用一个自动化测试框架,对于不同国家或者不同业务,有很多操作或者元素都是可复用的,因此我们采用了这两种模式根据不同业务创建不同的类,并且根据国家动态的创建不同的子类来管理,提高了整个框架的可维护性、可扩展性。
@tag的使用 (java)
有时候我们在执行测试的时候,并不需要跑完所有的测试用例,在这种情况下,我们可以将特定的场景分组并使用标签独立执行。格式是@+ 分组文本。使用不同的tag标注,在使用TestRunner之类的工具来执行测试的时候就可以选择不同的标签来跑某一个功能相关的测试用例或者只跑关键的scenario,这种方式在回归测试中使用很方便。