
软件开发的一般流程包括:编写、修改、测试和封装代码,而其中我们依靠后端服务和机器来完成各种工作,比如构建新软件包,安装依赖和执行测试。在Facebook的用户规模下,工程师每天需要执行数以千计的此类工作,而这将成为开发系统中的瓶颈。我们的目标是尽量减少工程师等待机器执行完成的时间,以便他们能够快速获得反馈,并将更多时间花在有创造性的任务上。
每个作业都在名为工作者的孤立环境中运行,并且这些作业分布在不同数据中心的不同主机上。工作者被预先配置为运行某些特定类型的作业 - 例如,Android作业将由具有正确代码库和依赖关系已的工作者执行。
这种类型的分布式系统需要一些机制来可靠且高效地将工作交付给适当的工作者。常见的解决方案包括从分布式队列到跟踪系统当前的作业状态并尝试优化分配工作负载的调度程序系统。但是,这些解决方案需要进行折中,例如,调度器往往成为可扩展性的瓶颈。在这篇文章中,我们描述了Jupiter,这是一个我们关注于“功能匹配”的调度服务程序。
对于工作者程序来说,功能本质上是对工作者服务程序的特征或者能够做什么的声明。例如RAM大小,工作者服务程序所在的数据中心,机器的当前负载因数,工作者服务程序锁连接到的智能手机的类型,预先加载到机器上的存储库或数据构件等。每个工作者服务程序都具有多种功能,每种功能都是一个或多个特征值的集合(例如,RAM大小是一个单值,但可能有几个预先加载的源代码存储库即为多值)。同样,每个作业都会对其需要的功能进行编码。例如,资源密集型构建需要一台强壮的机器;对某个版本的源代码库进行差异对比的CI作业最好由源代码已经预先加载的工作者服务程序执行;需要特定内核版本的作业只能由在该版本内核上运行的工作者服务程序执行;一组分布式的构建作业最好在某个集群中执行。
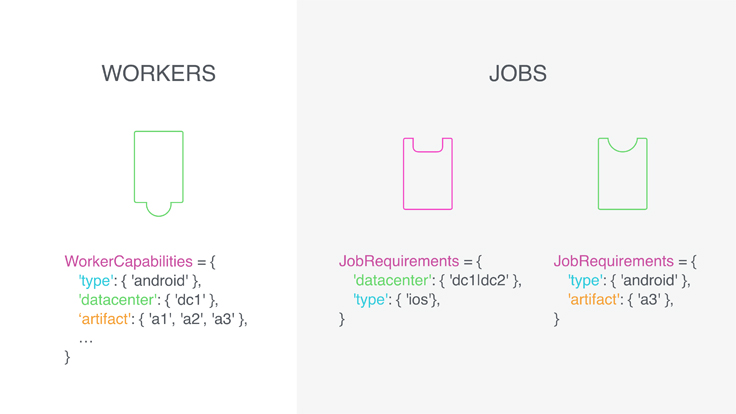
在系统中存在不断的更新和并发请求的情况下,调度从多维功能上将作业与工作者服务程序进行匹配是一个具有挑战的工程问题。Jupiter是一项服务,它擅长有效地响应来自工作者服务程序的工作请求,并跟踪系统中当前可用的工作,其中工作者服务程序和工作都可能具有多维的特征和需求。Jupiter保证了工作的原子性, 即使有多个请求正在运行,只有一个工作者服务程序将获得工作,一旦工作者服务程序确认接收工作,它就不能提供给任何其他的作业使用。
像许多其他的Facebook后端服务一样,Jupiter使用C ++编写,可通过Thrift访问。它可以横向扩展——它可以很容易地被分割,其中每个分割出来的个体都可以独立决定它的工作集合,并且系统中没有一个最高节点来负责所有的事情。Jupiter支持按照作业排队顺序进行作业处理,即像先入先出一样简单,但是也能够支持其他类型的作业优先级。在性能方面,它能够处理每秒数以万计的请求。
工作者服务程序发送请求给Jupiter来告知他们拥有的所有功能,Jupiter通过咨询其内部数据结构找到最佳匹配。在生产环境下的负载上,工作者服务程序获取请求的延迟大约为几十微秒。在收到工作时,工作者服务程序通过向Jupiter发送适当的请求来确认或拒绝该工作。在拒绝的情况下,作业被放置在请求中指定时间段的暂存区域中;在这段时间内不能给其他工作人员。Jupiter中有很多不同类型的确认API。例如,工作者程序可以向Jupiter发送租约请求,表明它已开始处理该工作,但只有在成功完成后才正式确认。在较高的层面上,所有Jupiter客户端都遵循获得作业、接收、处理作业并重返初始状态的周期工作模式。

因为Jupiter拥有队列中所有作业的信息,所以它可以做出高级别的调度决策,例如只有在某些必备工作完成之后才允许将作业给予工作者程序处理。对于许多使用场景, Jupiter的主要好处就是能够通过一群(异构)工作者程序高效地处理作业,并且它提供可靠性和原子性。在Facebook上,Jupiter能够支持不同的客户,如我们的资源管理系统One World以及我们的持续集成系统Sandcastle。数据和匹配模块之间的API边界很干净,所以与新系统集成非常容易。
明确Jupiter不是什么是很重要的,它不是数据持久层。如果需要记录作业数据,生产者层面负责这一点,Jupiter不断从持久层获取增量更新并保持最新的状态。这里的基本原理是双重的。首先,我们认为服务应该专注于一些事情,而不是对所有事情负责。其次,通过解耦作业存储和作业匹配,我们确保Jupiter不是整个系统的单点故障:如果Jupiter出现故障,生产者仍然能够对作业进行排队,一旦Jupiter恢复工作,所有的排队作业能完好无损地交付给工作者程序。Jupiter将数据提供者接口之后的所有操作都抽象出来,我们可以自由地选择任何存储引擎 ——无论是关系数据库还是分布式文件系统,或者在不需要持久性存储的情况下,在Jupiter自己的内存中存储。
Jupiter不具备全局的工作者程序状态信息(例如,哪些工人目前很忙或者谁能够处理给定的工作),并且不会关于什么作业应该送到哪里做出集中的决定。相反,作业能够被有效分配,因为工作者程序只请求他们能够处理的作业;作业本身的编码就制定了能够处理该作业的工作者程序需要具备的特征;Jupiter作为一个有效的仲裁者,将作业与工作程序进行做合适地匹配。
总之,Jupiter是一个高效的作业匹配服务,非常适合分布式系统的生产者/消费者类型。我们希望我们的经验和发现能够给工程界带来有益的发展。
【英文原文】https://code.facebook.com/posts/222017798302928
{测试窝原创译文,译者:初心}
译者简介:初心,东南大学在读硕士研究生
