

Cypress 和@playwright/test 是两个相互竞争的集成测试框架。 我们使用 Cypress 已经很长时间了,但最近决定将Cypress 测试迁移到 Playwright,全部 400 个。 为了提高速度和可靠性(未来的帖子),这绝对是值得的……但是,这意味着大量的手动工作!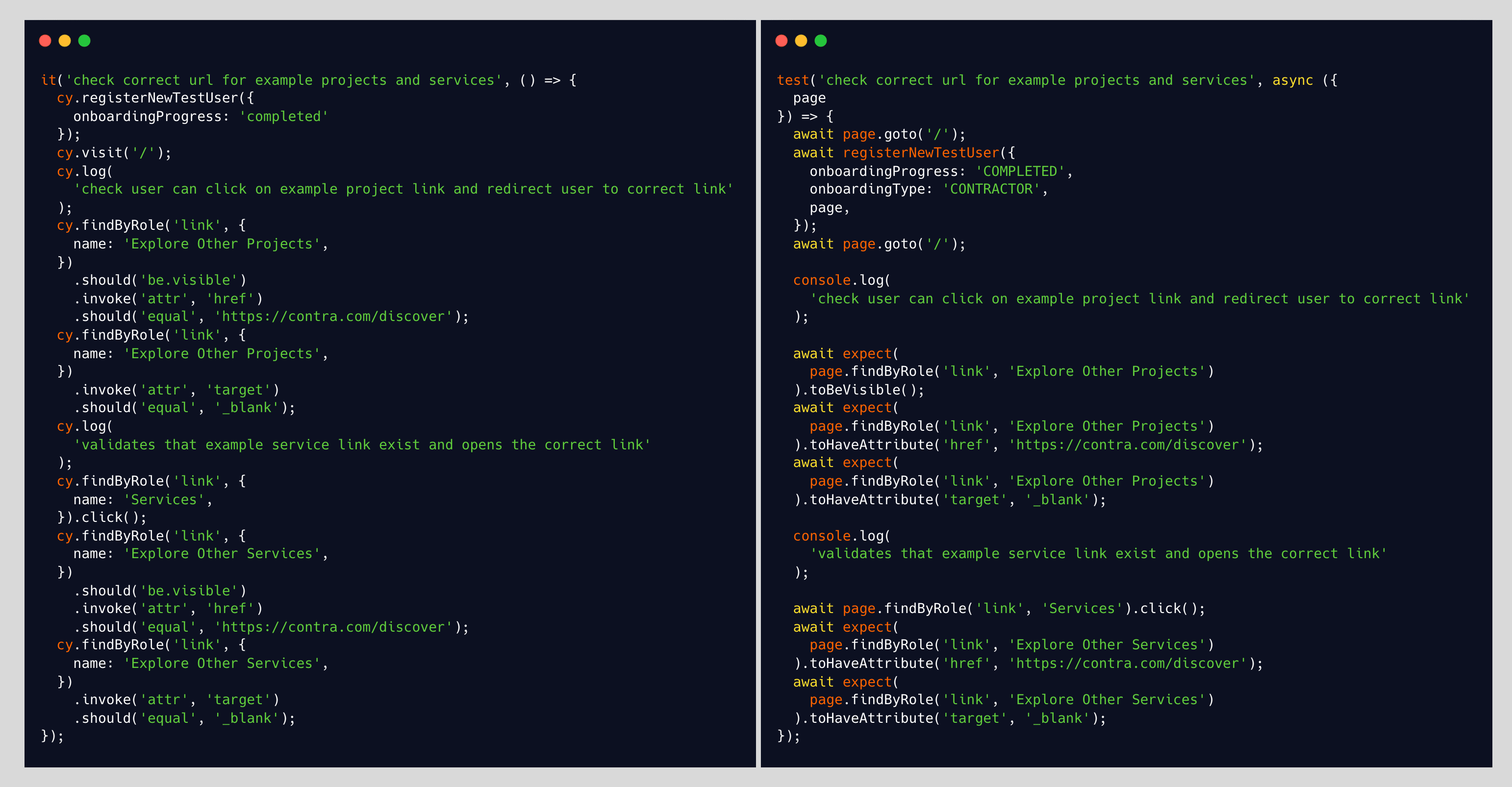
发现
在手动重写测试和观察 GitHub 的 Copilot 建议时,我想到了使用 GPT3 重写测试的想法。
如果不将旧的 Cypress 测试复制到同一个文件中,这些建议是非常随机的并且不是特别有用。 当我在开始编写测试之前将注释掉的 Cypress 代码复制到一个空的 Playwright 规范文件中时,Copilot 才开始提出明智的建议。那天我使用 Tab(完成建议)的次数比以往任何时候都多。 但是,使 Copilot 变得不那么有用的是:
- 它有时有效,有时无效
- 随着文件大小的增加,建议变得很糟糕
- 建议在新文件中丢失了以前代码的上下文
旁注:知道 Copilot 是使用 GPT3+Codex 实现的,这让我开始思考……鉴于我们已经手动重写了一些测试,为 GPT3 编写自动化(或半自动化)的提示会有多难 完全重写测试?我决定尝试使用 OpenAI 的 Playground。
OpenAI Playground
如果不熟悉 OpenAI 的 Playground 界面,它基本上是带有几个切换按钮的文本输入。输入一条指令并观察 API 完成响应,尝试匹配你提供的上下文和模式,例如:
常规文本是用户输入的提示。 突出显示的文本是响应。
我所需要的只是一个提示和一些例子。 这是我整理的内容:
为简洁起见,我跳过了代码示例,但你可以在此处找到完整的提示。值得注意的是,训练示例不是有效测试(如果执行它会失败),而是我们在所有测试中使用的模式集合。 此外,为了消除偏差,只使用了已经手动迁移的测试作为输入。以下是仅使用一个训练示例的结果,按照复杂性递增的顺序列出。
一个简单的测试,没有新patterns:
上述测试的输出正是我在代码库中编写的内容。一个好的开始!一个简单的测试,只介绍几个容易推导的概念:
这就是我们的代码库中已有的。
 我们在使用 GPT3 之前编写的迁移。
我们在使用 GPT3 之前编写的迁移。
上述示例的有趣之处在于,训练数据从未见过 toBeChecked 或 toBeDisabled。
带有一堆看不见的概念的更复杂的测试:
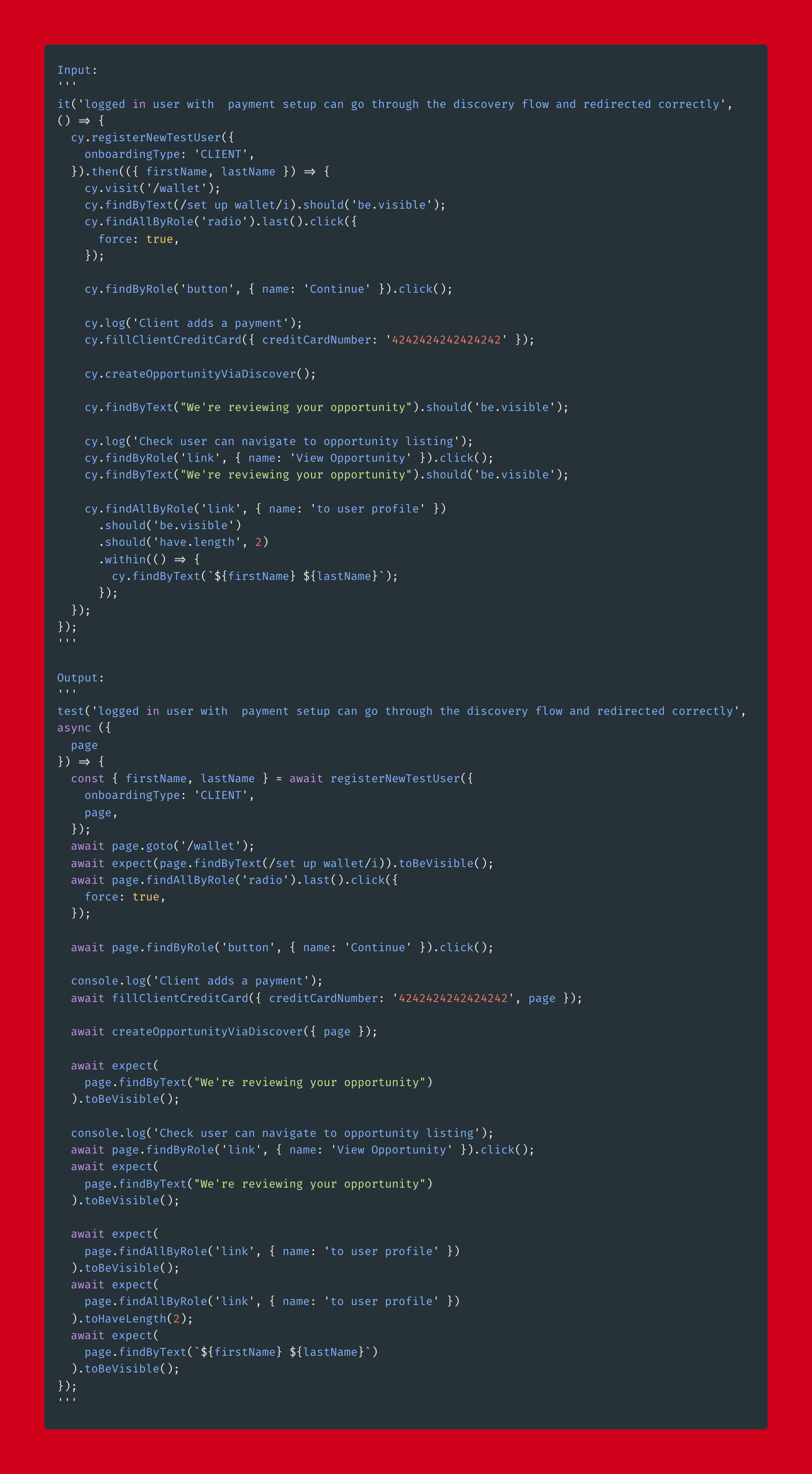 有一些错误,但总体上非常接近!
有一些错误,但总体上非常接近!
在我们的代码库中是:
 手动迁移测试
手动迁移测试
与紫色示例类似,GPT3 真正令人印象深刻的是它如何处理以前从未见过的场景。 整个 registerNewTestUser 回调在训练数据集中不可用。 上次测试的实现大不相同。 尽管如此,这主要是因为迁移测试的人在重写测试时做出了固执己见的选择(例如,用 has-text 来支持基于 nth 的选择器)。 否则,它们在功能上是等价的。
总的来说,这真的很酷! 写这篇文章比训练 GPT3 做一些节省数百小时的事情花费的时间更长。 在实践中,我唯一一次观察到 GPT3 给出了意想不到的建议是在它之前没有看到那个模式/助手的时候。 在那些情况下,我只是用那个特定的用例示例扩展了训练示例。对我们来说,这是对工作流程的一个相当(令人愉快的)改变。 随着我们继续重写剩余的 300~ 个测试,工作流程主要是 [复制粘贴]、[评估]、[应用][为新案例扩展训练示例]。
 观看 OpenAI Playground 键入响应永远不会过时!
观看 OpenAI Playground 键入响应永远不会过时!
我们最初将主要按照 GPT3 的建议迁移所有测试,然后返回并寻找改进的机会。总而言之,这是 GPT3 的一个非常巧妙的应用,也为我们的团队节省了大量时间,我觉得我们只是触及了可能性的表面!
