
浏览器是一个非常复杂的软件。由于如此巨大的复杂性,保持快速开发速度的唯一方法是通过广泛的 CI 系统,该系统可以让开发人员确信他们的更改不会引入错误。但我们的 CI 规模如此巨大,我们一直在寻找减少负载的方法,同时保持高标准的产品质量。所以,我们想搞清楚是否可以使用机器学习来达到更高的效率。
大规模持续集成
在 Mozilla,我们有大约 85,000 个测试文件。每个文件中都包含许多测试函数。这些测试需要在所有支持的平台(Windows,Mac,Linux,Android)上,组合各种配置(PGO,Debug,ASan等)和运行时参数(站点隔离,WebRender,多进程等)执行测试。
虽然我们不会针对上述所有可能的组合进行测试,但我们仍然有 90 多种独特的配置需要测试。换句话说,对于开发人员推送到存储库的每个更改,可能会以90种不同的方式运行所有85k个测试。在工作日,我们统计大概会有近 300 次推送(包括测试分支)。如果我们在每次推送上在每个配置上运行每个测试,我们每天将运行约23亿个测试文件!虽然我们在一定程度上投入了资金,但作为独立的非营利组织,我们的预算是有限的。
那么我们如何保持持续集成负载可控呢?首先,我们认识到,这九十种独特配置中的一些比其他配置更重要。许多不太重要的配置只运行一小部分测试,或者一天只运行少数几次推送,或者两者都是。其次,在我们的测试分支中,我们依赖开发人员指定哪些配置和测试与他们的更改最相关。第三,我们使用集成分支。
基本上,当一个补丁被推送到集成分支时,我们只对它运行一小部分测试。然后,我们定期运行所有内容,并聘请代码警长(code sheriffs)来确定我们是否遗漏了某些回归。如果有遗漏,就会回退有问题的补丁。一旦一切正常,集成分支会定期合并到主分支。

Treeherder 上的 Mozilla 中心推送示例:单个推送运行的任务子集。
高效测试的新方法
上面这些方法多年来一直为我们服务,但事实证明它们仍然非常昂贵。即使进行了所有这些优化,我们的 CI 仍然每天运行大约 10 个计算年!部分问题在于,我们一直在使用朴素的启发式方法来选择要在集成分支上运行的任务。启发式方法根据任务过去失败的频率对任务进行排名。排名与补丁的内容无关。因此,修改 README 文件的推送将运行与启用站点隔离的推送相同的任务。此外,确定要在测试分支上运行哪些测试和配置的责任已转移到开发人员自己身上。这浪费了他们宝贵的时间,并倾向于过度选择测试。
大约一年前,我们开始问自己:我们如何才能做得更好?我们意识到,CI 的当前实施在很大程度上依赖于人为干预。如果我们可以使用历史数据将补丁与测试相关联会怎样?我们可以使用机器学习算法来找出要运行的最佳测试集吗?我们假设,可以通过运行更少的测试来节省资金,同时更快地获得结果,并减轻开发人员的认知负担。在这个过程中,我们将构建必要的基础设施,以保持我们的 CI 流水线高效运行。
享受历史失败的乐趣
基于机器学习的解决方案的先决条件是收集足够大且足够精确的回归数据集。从表面上看,这似乎很容易。我们已经将所有测试执行的状态存储在名为 ActiveData 的数据仓库中。但实际上,由于以下原因,实际很难做到。
由于我们只在任何给定的推送上运行测试的子集(然后定期运行所有测试),因此究竟是何时引入的错误并不总是很明显。请考虑以下方案:
| Patch | 测试 A | 测试 B |
|---|---|---|
| 补丁1 | 通过 | 通过 |
| 补丁2 | 失败 | 不运行 |
| 补丁3 | 失败 | 失败 |
很容易看出,补丁 2 导致了“测试 A”出现错误,因为这是它最初开始出现错误的地方。然而,对于“测试 B”的错误,我们无法确定是由补丁 2 还是补丁 3 引起的。想象一下某种情况,在最后一个 PASS 和第一个 FAIL 之间有 8 个补丁。这增加了很多不确定性!
间歇性故障也使收集数据变得困难。有时,由于各种不同的原因,测试用例可以在同一份代码库有通过和失败两种结果。事实证明,我们无法确定补丁 2导致“测试 A”运行失败!除非我们重新运行失败的次数足够多,以便在统计上有信心。更糟糕的是,补丁本身可能首先引入了间歇性故障,所以我们也不能仅仅因为失败是间歇性的就认为不是这个补丁导致的。
我们的启发式方法
为了解决这些问题,我们构建了相当庞大而复杂的启发式算法来预测哪些错误是由哪个补丁引起的。例如,如果稍后回退补丁,我们会检查回退推送的测试状态。如果它们仍然失败,我们可以非常确定故障不是由于补丁造成的。相反,如果通过,我们可以非常确定补丁有问题。
有些失败用例是由人类分类的,这对我们是有利的。代码警长的部分工作是注释失败(例如,“间歇性”或“后续通过提交修复”)。这些由人类分类的情况在测试缺失或测试间歇性失败时有很大帮助。不幸的是,由于不断提交的补丁和发生的失败数量之多,无法达到 100% 的准确性。因此,我们甚至使用启发式方法来评估分类的准确性!
处理缺失数据的另一个技巧是填补缺失的测试。我们选择在早期没有运行的推送上运行测试,以确定造成失败的推送。目前,警卫手动执行此操作。但是,在未来的某些情况下有计划自动化。
收集有关修补程序的数据
我们还需要收集有关补丁本身的数据,包括修改的文件和差异。这使我们能够与测试失败数据相关联。通过这种方式,机器学习模型可以确定给定补丁最有可能失败的测试集。
收集有关补丁的数据要容易得多,因为它是完全确定的。我们遍历 Mercurial 存储库中的所有提交,使用 rust-parsepatch 项目解析补丁,并使用 rust-code-analysis 项目分析源代码。
设计训练集
现在我们有了补丁和相关测试(通过和失败)的数据集,我们可以构建一个训练集和一个验证集来教我们的机器如何为我们选择测试。
90% 的数据用作训练集,10% 用作验证集。拆分必须小心完成。验证集中的所有补丁的提交时间都必须位于训练集中的补丁之后。如果我们随机拆分,我们会将未来的信息泄漏到训练集中,导致结果模型有偏差,并人为地使其结果看起来比实际更好。
在现实世界中,我们无法展望未来。模型无法知道下周会发生什么,而只能知道到目前为止发生了什么。为了正确评估,我们需要假装我们在过去,并且未来的数据(相对于训练集来说)必须是无法访问的。

图表显示训练集 (90%) 和验证集 (10%) 的比例
构建模型
我们使用测试用例、补丁和它们之间的链接的作为特征来训练一个 XGBoost 模型,例如:
- 当修改改文件时,此测试失败的频率如何?
- 源文件在目录树中与测试文件相距多远?
- 在 VCS 历史记录中,源文件与测试文件一起修改的频率如何?
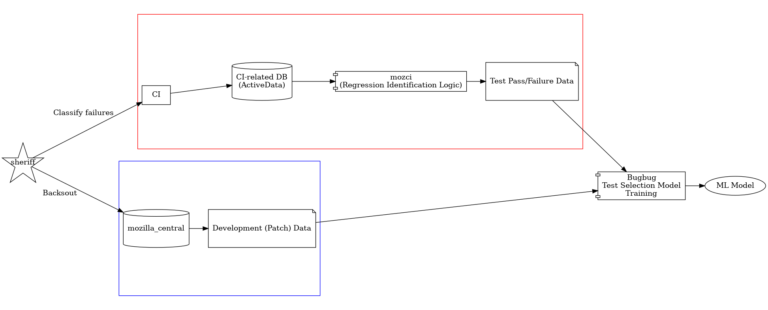
模型训练基础结构的完整视图
模型的输入是一个元组(TEST,PATCH),标签是二进制 FAIL 或 NOT FAIL。这意味着我们有一个能够处理所有测试的模型。
鉴于我们有数以万计的测试,即使我们的模型准确率为 99.9%(这是相当准确的,每 1000 次评估只有一个错误),我们仍然会在几乎每个补丁上犯错误!幸运的是,在我们的领域中,与误报(由模型为给定补丁选择但不会失败的测试)相关的成本并不像试图识别人脸用于警务目的那样高。我们付出的唯一代价是运行一些无用的测试。同时,我们避免了运行数百个,因此最终结果是节省了大量资金!
随着开发人员持续在代码库上更新代码和测试,模型也需要不断进化。因此,我们目前每两周重新训练一次模型。
优化配置
选择要运行的测试后,我们可以通过选择测试的运行位置来进一步改进选择。换句话说,选择应该运行的配置集。我们使用收集的数据识别任何给定测试的冗余配置。例如,是否有必要在Windows 7和Windows 10上同时运行该测试?为了识别这些冗余,我们使用类似于频繁项集挖掘的解决方案:
- 收集失败的测试和配置的统计信息。
- 计算“支持度”,即 X 和 Y 同时失败的次数与它们两者都运行的次数之比。
- 计算“置信度”,即 X 和 Y 同时失败的次数除以 X 和 Y 同时运行且只有一个失败的次数。
我们只选择支持读高(支持度低意味着我们没有足够的证据)且置信度高(置信度低意味着我们有很多情况下冗余不适用)的配置组。
一旦有了要运行的一组测试,以及其结果是否依赖于配置的信息,以及运行它们的一组计算机(及其相关成本),就可以制定一个数学优化问题,我们用混合整数规划求解器来解决。这样,我们可以轻松地更改想要实现的优化目标,而无需对优化算法进行更改。目前,优化目标是选择运行测试的最便宜的配置。
优化目标:最小化下式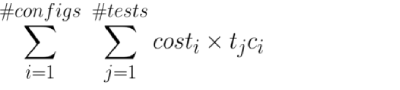
约束: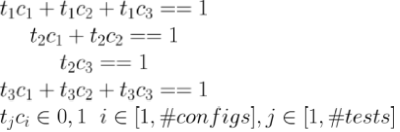
上面是一个具有三个测试和三个配置的优化问题的实例。测试 1 和测试 3 完全独立于平台。测试 2 必须在配置 3 以及配置 1 或配置 2 之一上运行。
使用模型
为了使机器学习模型有用,我们在Heroku上搭建一个服务,使用专用的 worker dynos 来处理请求,并使用 Redis 队列在后端和前端之间搭建桥梁。前端提供了一个简单的 REST API,因此用户仅需指定他们感兴趣的 push(通过分支和最顶部的版本识别)。后端将自动使用 mozilla-central 克隆确定的更改的文件及其内容。
根据队列中要分析的推送数和推送的大小,服务可能需要几分钟来计算结果。因此,我们确保永远不会为任何给定的推送生成多个任务。我们在计算后缓存结果,这允许使用者异步查询,并定期轮询以查看结果是否准备就绪。
我们目前在集成分支上使用该服务。当开发人员在测试分支上运行特殊的 mach try auto 命令时,也会使用它。将来,我们还可能使用它来确定开发人员应该在本地运行哪些测试。
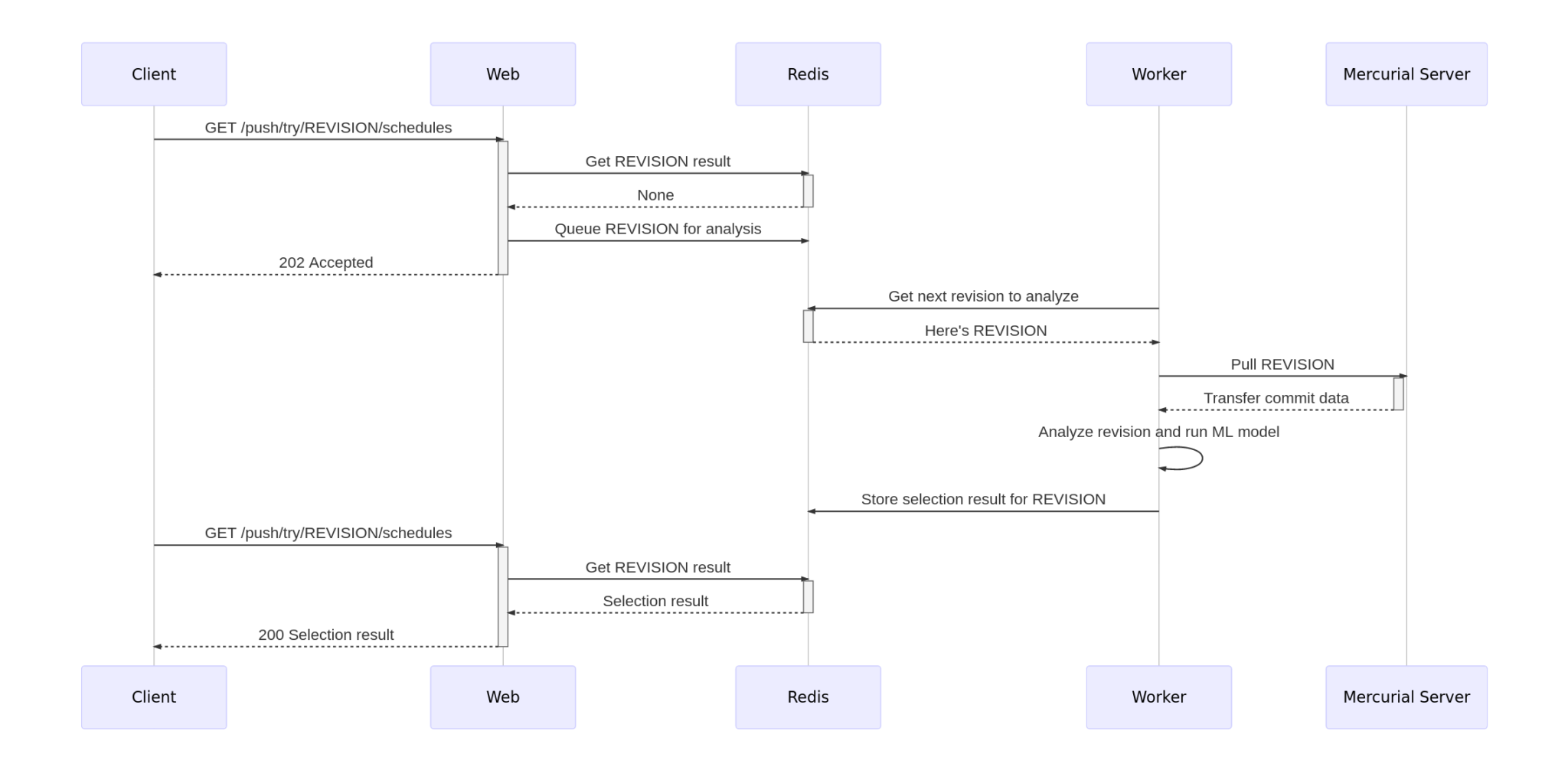
上图描述基础设施中各个参与者之间通信的序列图。
测量和比较结果
从这个项目一开始,我们就觉得能够通过运行比较实验来衡量方法是否有效,并确信对算法的更改实际上是对现状的改进,这一点至关重要。在任务计划算法中,我们实际上关心两个变量:
- 使用的资源量(以小时或美元为单位)。
- 错误检测率。也就是说,直接在推送中捕获的引入错误的百分比。换句话说,我们不必依靠人类来以找出哪个 push 是罪魁祸首。
我们定义了指标:
scheduler effectiveness = 1000 * regression detection rate / hours per push
任务计划有效性 = 1000 * 错误检测率 / 每个 push 执行时长
此指标越高,任务计划算法越有效。既然我们有了度量标准,我们就发明了“影子调度器”的概念。影子调度程序是在每次推送时运行的任务,它会影响实际的调度算法。刚开始时,他们只输出默认安排的任务,而不是实际安排的任务。每个影子调度程序对机器学习服务返回的数据的解释可能略有不同。或者,他们可能会在机器学习模型建议的基础上运行其他优化。
最后,我们编写了一个 ETL 来查询所有这些影子调度程序的结果,计算每个影子调度程序的 scheduler effectivenes 指标,并将它们全部绘制在仪表板中。目前,我们正在监控和微调大约十几种不同的影子调度程序,以找到最佳结果。一旦我们确定了获胜者,我们就会将其设置为默认算法。然后我们重新开始这个过程,创建进一步的实验。
结论
该项目的早期结果非常有希望。与我们之前的解决方案相比,我们集成分支上的测试任务数量减少了 70%!与没有测试选择的 CI 系统相比,几乎增加了99%!我们还看到我们的 mach try auto 工具的采用速度相当快,这表明可用性有所提高(因为开发人员不再需要考虑选择什么)。但还有很长的路要走!
我们需要提高模型选择配置和默认配置的能力。我们的回归检测启发式方法和数据集的质量需要改进。我们尚未对 mach try auto 实施可用性和稳定性修复。
虽然我们不能做出任何保证,但我们很乐意以一种对 Mozilla 以外的组织有用的方式打包模型和服务。目前,这项工作是一个更大项目的一部分,该项目包含最初为帮助管理 Mozilla 的 Bugzilla 实例而创建的其他机器学习基础设施。敬请期待!
如果您想了解有关此项目或 Firefox CI 系统的更多信息,请随时在我们的 Matrix 频道 #firefox-ci:mozilla.org 上提问。
{测试窝原创译文,译者:lukeaxu}
