
导言
- 对抗性攻击:测试模型有助于发现可能的攻击。与其让这种攻击在生产环境中发生,不如在部署模型之前用对抗性实例对其进行测试,以提高其稳健性。
- 数据完整性和偏差: 从大多数来源收集到的数据通常都是非结构化的,可能会反映出人类的偏见,可以在训练过程中加以模拟。 这种偏见可能是针对特定群体的,如性别、种族、宗教或性取向,根据使用规模的不同,会对社会造成不同的影响。在评估过程中,偏见可能会被忽略。
- 发现失败模式: 在尝试将机器学习系统部署到生产中时,可能会出现失败模式。这些故障可能是由于性能偏差故障、稳健性故障或模型输入故障造成的。评估指标可能会忽略其中一些故障,尽管它们可能是问题的信号。一个准确率为 90% 的模型意味着,该模型很难对 10% 的数据进行归纳。这可以促使您检查数据并查找错误,从而更好地了解如何解决问题。它并非包罗万象,因此需要针对可能遇到的情况进行结构化测试,以帮助检测故障模式。
本文展示了机器学习测试与 “普通 “软件测试的不同之处,以及为什么仅评估模型性能是不够的。你将了解如何测试机器学习模型,以及应遵循哪些原则和最佳实践。
测试机器学习模型存在的问题
软件开发人员编写代码是为了产生确定的行为。测试能明确识别代码中哪一部分出现故障,并提供相对一致的覆盖率衡量标准(如覆盖的代码行数)。它在两个方面对我们有帮助:
- 质量保证;软件是否按照要求运行,以及
- 在开发和生产过程中发现缺陷和瑕疵。
数据科学家和机器学习工程师通过向模型提供示例和设置参数来训练模型。模型的训练逻辑产生行为。在测试机器学习模型时,这一过程会带来以下挑战:
- 缺乏透明度。许多模型像黑盒子一样工作。
- 建模结果不确定。许多模型依赖于随机算法,在(重新)训练后不会产生相同的模型。
- 通用性。模型需要在训练环境之外的其他环境中持续工作。
- 覆盖范围概念不明确。目前还没有既定的方法来表达机器学习模型的测试覆盖率。在机器学习中,”覆盖率 “并不像软件开发中那样指代码行数。相反,它可能与输入数据和模型输出分布等概念有关。
- 资源需求。对机器学习模型进行连续测试需要资源,而且时间密集。
这些问题使得我们很难理解模型性能低下的原因、解释结果,并确保即使输入数据分布发生变化(数据漂移)或输入和输出变量之间的关系发生变化(概念漂移),模型也能正常工作。
评估与测试
许多从业者可能只依赖于机器学习模型的性能评估指标。然而,评估并不等同于测试。了解两者的区别非常重要。
机器学习模型评估侧重于模型的整体性能。这种评估可能包括性能指标和曲线,也许还有错误预测的例子。这种模型评估是监控不同版本模型结果的好方法。请记住,它并不能告诉我们很多失败背后的原因和具体的模型行为。
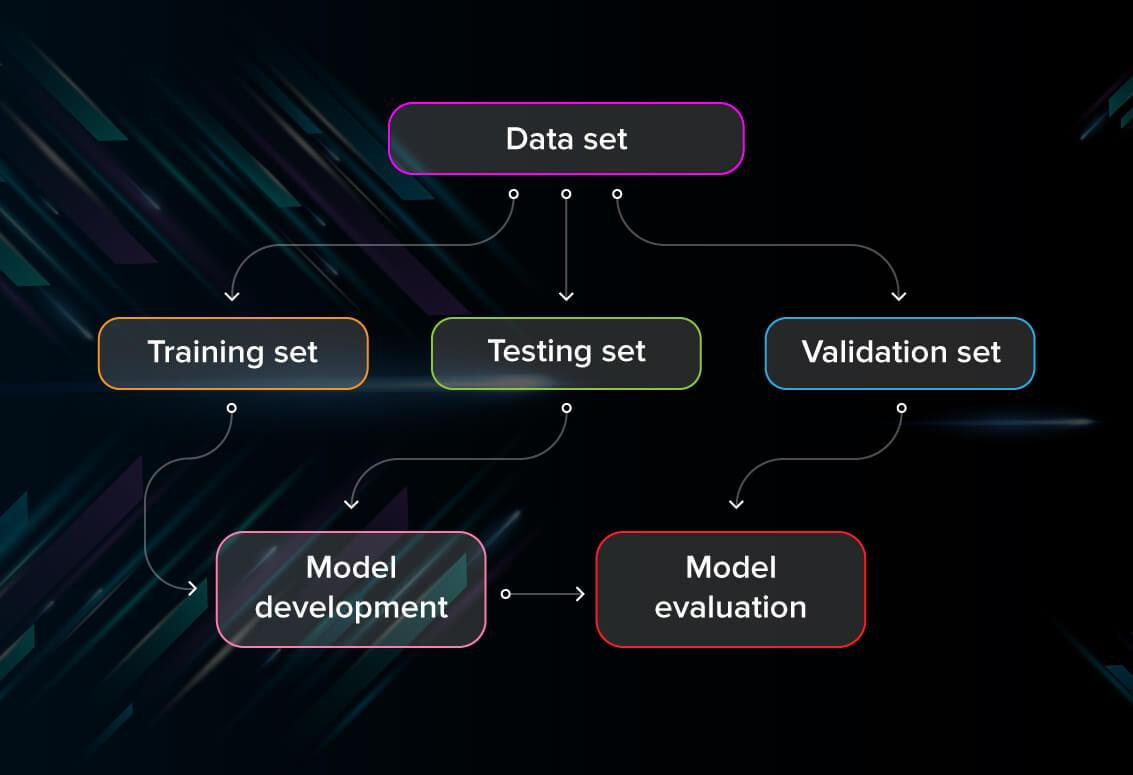
例如,模型在某个关键数据子集中的性能可能会下降,而其整体性能却不会改变,甚至还会提高。在另一种情况下,基于新数据的模型再训练不会产生性能变化,反而可能会对特定人口群体产生未被察觉的社会偏见。
另一方面,机器学习测试不仅仅是评估模型在数据子集上的性能。它能确保机器学习系统的综合部分有效工作,以达到预期的结果质量水平。可以说,它能帮助团队指出代码、数据和模型中的缺陷,从而加以修复。
原则与最佳实践
测试并非易事,而测试机器学习模型更是难上加难。在处理动态输入、黑盒模型和不断变化的输入/输出关系时,需要为意外事件准备好工作流程。
因此,在软件测试中值得遵循这些既定的最佳实践:
- 在引入新组件、模型或数据后,以及在模型重新训练后进行测试。
- 在部署和生产前进行测试。
- 编写测试以避免将来出现已知的错误。
测试机器学习模型有额外的要求。此外,还需要遵循针对机器学习问题的测试原则:稳健性、可解释性、可重复性。
稳健性,稳健性要求模型即使在数据和关系发生剧烈实时变化的情况下也能产生相对稳定的性能。可以通过以下方式增强稳健性:
- 建立团队遵循的机器学习流程。
- 明确测试稳健性(如漂移、噪声、偏差)。
- 针对部署模型制定监控策略。
可解释性,保持可解释性可让你了解模型的特定方面:
- 模型是否能预测应有的输出(例如,基于人工评估者)。
- 输入变量对输出的贡献。
- 数据/模型是否存在潜在偏差
可重复性,模型会因参数调整、重新训练或新数据而发生变化,无论在哪个平台上使用,要想在生产中推广模型,都需要确保结果的可重复性。
可重复性包括很多方面。虽然这不是一篇关于这个主题的文章,但这里有一些确保模型可重现的提示:
- 通过确定性随机数发生器使用固定的随机种子。
- 确保组件以相同的顺序运行,并接收相同的随机种子。
- 即使是初步迭代也要使用版本控制。
如何测试机器学习模型
许多现有的机器学习模型测试实践都遵循人工错误分析(如故障模式分类),因此速度慢、成本高且容易出错。适当的机器学习模型测试框架应将这些做法系统化。
可以将软件开发测试类型映射到机器学习模型,将其逻辑应用于机器学习行为:
- 单元测试。检查单个模型组件的正确性。
- 回归测试。检查模型是否崩溃,并测试之前遇到的错误。
- 集成测试。检查不同的组件是否能在机器学习管道中相互配合。
具体的测试任务可能属于不同的类别(模型评估、监控、验证),这取决于具体的问题案例、环境和组织结构。本文侧重于机器学习建模问题的特定测试(训练后测试),因此不涉及其他测试类型。请确保将机器学习模型测试集成到更广泛的机器学习模型监控框架中。
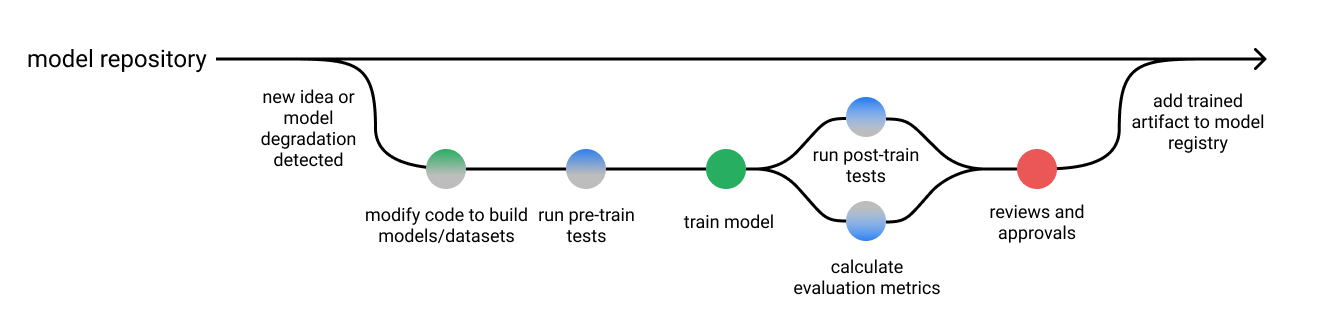
测试训练有素的模型
对于代码,可以编写手动测试用例。对于机器学习模型来说,这不是一个很好的选择,因为无法覆盖多维输入空间中的所有边缘情况。
相反,可以针对现实世界中的问题,通过监控、数据切片或基于属性的测试来测试模型性能。
可以将其与专门检查训练模型内部行为的测试类型(训练后测试)相结合:
- 方差检验
- 方向预期测试
- 最小功能测试
不变性检验
不变性检验定义了预期模型输出不受影响的输入变化。
测试不变性的常用方法与数据增强有关。可以将修改过和未修改过的输入示例配对使用,并查看这对模型输出的影响程度。
其中一个例子是检查一个人的名字是否会影响其健康。默认假设可能是两者之间不存在任何关系。如果基于这一假设的测试失败,则可能意味着姓名和身高之间存在隐藏的人口统计学联系(因为数据涵盖了多个国家,这些国家的姓名和身高分布各不相同)。
定向期望测试
可以运行定向期望测试来定义输入分布变化对输出的预期影响。
一个典型的例子是在预测房价时测试有关浴室数量或房产面积的假设。浴室数量越多,意味着预测的价格越高。看到不同的结果可能揭示了对输入和输出之间关系或数据集分布的错误假设(例如,小型单间公寓在昂贵社区中的比例过高)。
最小功能测试
最小功能测试可帮助你确定单个模型组件的行为是否符合预期。这些测试背后的原因是,基于输出的整体性能可能会掩盖模型中即将出现的关键问题。
以下是测试单个组件的方法:
- 创建对模型来说 “非常容易 “预测的样本,以了解它们是否能持续提供此类预测。
- 测试符合特定标准的数据片段和子集(例如,仅在短句数据上运行语言模型,以了解其 “预测短句 “的能力)。
- 测试人工错误分析中发现的故障模式。
测试模型技能
软件开发测试通常侧重于项目代码。然而,这并不总是适用于机器学习工作流,因为代码并不是唯一的元素,而且行为并不能如此清晰地映射到代码片段。
组织机器学习测试的一种更 “行为化 “的方式是关注期望从模型中获得的 "技能" 。例如,可以检查自然语言模型是否能获取词汇、名称和参数信息。从时间序列模型中,应该能够识别趋势、季节性和变化点。
可以通过检查上述讨论过的模型属性(即不变性、定向期望、最小功能),以编程方式测试这些技能。
测试性能
测试一个完整的模型需要花费大量时间,尤其是在进行集成测试时。
为了节省资源并加快测试速度,可以测试模型的小部分内容(例如,检查梯度下降的单次迭代是否会导致损失减少),或者只使用少量数据。还可以使用更简单的模型来检测特征重要性的变化,并提前捕捉概念漂移和数据漂移。
对于集成测试,在每次迭代时都要持续运行简单的测试,并在后台运行更大更慢的测试。
结论
测试是一个迭代过程,在处理可能需要海量数据和长时间模型训练的机器学习项目时,测试可能会很困难。
