

简介:文章描述了一个统计不同单词出现次数的常见面试题目,并使用了不同的语言实现并且比较它们之间的性能。对于每一种语言,均包含实现的简单版本与优化版本。
在担任面试官的许多年中,我最喜欢提问的问题之一就是:
统计标准输入不同单词的数量,并按照单词出现的频次排序后输出单词与统计频次。
例如,有以下输入:
The foo the foo the defenestration the
程序执行后应输出以下结果:
the 4
foo 2
defenestration 1
我认为这个问题好在并不比解决 FizzBuzz 容易,但又不至于像“在草稿纸上反转二叉树”那样困难。这是一个在程序员编程生涯中极有可能遇到的问题,通过这个问题可以考察其对文件 I/O ,哈希表,以及编程语言中排序函数的理解。另外,排序的部分还暗藏玄机,因为大多数语言的哈希表是无序存储的,即使说它有序,也是按照键名或插入顺序而不是其值来排序的。
当面试者对问题有一个初步的解决后,您可以从不同的角度或方面将问题继续深入:考虑大小写?标点符号?相同频次单词间的顺序?程序性能的瓶颈在于?用 O 表示一下算法复杂度?内存占用情况如何?有 1GB 输入时候估计程序需要执行多长时间?如果输入有 1TB ,程序仍有效吗等等。或者另一方面,从软件工程角度考察,讨论关于错误处理,可测性以及生成命令行调用程序等等。
基本的程序处理流程是:按行读入,转换成小写,分割单词,累加单词数目到哈希表;将哈希表转换为(单词,频次)列表,然后按照频次从大到小排序;输出列表。
在 Python 中,一个显而易见的解决方案可能如下所示(省略导入):
counts = {}
for line in sys.stdin:
words = line.lower().split()
for word in words:
counts[word] = counts.get(word, 0) + 1
pairs = sorted(counts.items(), key=lambda kv: kv[1], reverse=True)
for word, count in pairs:
print(word, count)
如果面试者熟悉 Python ,那么他还有可能使用 collections.defaultdict 或 collections.Counter – 后文中还会有介绍。 至于这种情况,我会和他讨论其底层究竟是如何实现的,或者使用普通字典如何实现等。
顺便一提,这个问题可以说是几十年前两位计算机科学家之间决斗的开端。Jon Bentley 邀请了 Donald Knuth 在这个问题上展示下如何进行 “literate programming” ,然后写入并发表了一篇有 10 多页的文章。后来 Doug McIlroy( Unix 管道作者)写出了一个单行的 Unix Shell 解决这个问题。

总之,我接触这个问题确实有挺长时间了,所以借此整理下。文章里使用多种语言来实现解决这个问题,并且在其基础实现与优化版本之间比较了性能。尽管这篇文章有许多代码实例,但是若您想查看全部源代码还请移步我的仓库 benhoyt/countwords 。或者您可以直接跳转到性能比较结果部分.
问题描述与约束
每个程序从标准输入读入数据,然后按照单词出现频次从大到小输出单词与频次,单词与频次之间使用空格分隔。为了保证结果简单一致,另外增加一些约束如下:
- 大小写:程序应将单词转为小写进行统计,例如 “The the THE” 统计为 “the 3” 。
- 单词:任何用空格分隔的东西——忽略标点符号。这确实降低了程序的用处,但我不希望这成为一场标记之战。
- ASCII:可以只支持 ASCII 来处理空格和小写操作。
- 排序:如果两个词的相同,则它们在输出中的顺序无关紧要。
- 线程:它应该在单台机器上的单线程中运行。
- 内存:不要将整个文件读入内存。逐行缓冲是可以的,或者以最大缓冲区大小为 64KB 的块进行缓冲。也就是说,可以将整个 word-count map 保存在内存中(我们假设输入是真实语言的文本,并不全都是随机的唯一单词)。
- 文本:假设输入文件是文本,行的长度少于缓冲区大小。
- 安全:即使是程序的优化版本,也尽量不要使用不安全的语言特性,也不要使用汇编。
- Hashing: 对于高级语言例如 Python 等不要尝试自己实现哈希操作(优化的 C 版本除外)。
- Stdlib:只使用该语言的标准库函数。
测试输入文件是重复 10 次的 King James Bible . 文本中的引用符号已经使用ASCII中的引用符号替换。
准备就绪,现在就让我们开始编程吧!
Python
Python 代码可能使用 collections.Counter 去实现。 感谢 Raymond Hettinger 让 Python 的 collections 库更好用! Python 代码大概像下面这样:
simple.py
counts = collections.Counter()
for line in sys.stdin:
words = line.lower().split()
counts.update(words)
for word, count in counts.most_common():
print(word, count)
这是一个面向 Uinicode 字符的程序,并且在现实中很实用。它的效率不可谓不高,因为所有的低阶函数都是用 C 来实现的,包括:读取文件,转换小写,分割单词,更新计数器以及 Counter.most_common 实现的排序。
但是,我们仍然要尝试优化它。Python 有一个 profiling 模块 可以通过 python3 -m cProfile 来调用。我注释掉了程序 print 性能统计的部分。根据执行时间排序 -s tottime 的统计结果如下:
$ python3 -m cProfile -s tottime simple.py <kjvbible_x10.txt
6997799 function calls (6997787 primitive calls) in 3.872 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
998170 1.361 0.000 1.361 0.000 {built-in method _collections._count_elements}
1 0.911 0.911 3.872 3.872 simple.py:1(<module>)
998170 0.415 0.000 0.415 0.000 {method 'split' of 'str' objects}
998171 0.405 0.000 2.388 0.000 __init__.py:608(update)
998170 0.270 0.000 0.622 0.000 {built-in method builtins.isinstance}
998170 0.182 0.000 0.351 0.000 abc.py:96(__instancecheck__)
998170 0.170 0.000 0.170 0.000 {built-in method _abc._abc_instancecheck}
998170 0.134 0.000 0.134 0.000 {method 'lower' of 'str' objects}
5290 0.009 0.000 0.018 0.000 codecs.py:319(decode)
5290 0.009 0.000 0.009 0.000 {built-in method _codecs.utf_8_decode}
1 0.007 0.007 0.007 0.007 {built-in method builtins.sorted}
7/1 0.000 0.000 0.000 0.000 {built-in method _abc._abc_subclasscheck}
1 0.000 0.000 0.007 0.007 __init__.py:559(most_common)
1 0.000 0.000 0.000 0.000 __init__.py:540(__init__)
1 0.000 0.000 3.872 3.872 {built-in method builtins.exec}
7/1 0.000 0.000 0.000 0.000 abc.py:100(__subclasscheck__)
7 0.000 0.000 0.000 0.000 _collections_abc.py:392(__subclasshook__)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
1 0.000 0.000 0.000 0.000 {method 'items' of 'dict' objects}
可以观察到:
- 因为程序是按行读入,因此可以看到总共有 998,170 行输入,循环中的每一个函数都要调用这么多次。
- 从 simple.py 行可以看出执行Python字节码是多么得慢—主循环是执行了 998,170 次的纯 Python 代码。
- str.split 执行也相对较慢,可能是因为有大量分配空间以及拷贝动作。
- Counter.update 内部调用了 isinstance ,所以 cumtime 花费了许多时间。而若直接调用C函数 _count_elements 则会带来一些不安全因素。
据此分析,优化能做的最主要的事情是减少 Python 中循环调用的次数,从而减少其中各个函数的调用次数。所以如下优化后的程序每次读取大小为 64KB 的块:
optimized.py
counts = collections.Counter()
remaining = ''
while True:
chunk = remaining + sys.stdin.read(64*1024)
if not chunk:
break
last_lf = chunk.rfind('\n') # process to last LF character
if last_lf == -1:
remaining = ''
else:
remaining = chunk[last_lf+1:]
chunk = chunk[:last_lf]
counts.update(chunk.lower().split())
for word, count in counts.most_common():
print(word, count)
之前,程序每行平均处理 42 个字符,现在一次性大概处理 65,536 个字符。现在程序以更高的效率解决了原来的问题,因为直接调用 C 函数的比重提升了。很多优化方法也使用了这个基本的方法—每次处理更多的数据。
下面是再次执行性能分析命令的结果。 _count_elements 和 str.split 仍然占用了大多数的执行时间,但是我们将调用次数从 998,170 优化到了 662 。
$ python3 -m cProfile -s tottime optimized.py <kjvbible_x10.txt
7980 function calls (7968 primitive calls) in 1.280 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
662 0.870 0.001 0.870 0.001 {built-in method _collections._count_elements}
662 0.278 0.000 0.278 0.000 {method 'split' of 'str' objects}
1 0.080 0.080 1.280 1.280 optimized.py:1(<module>)
662 0.028 0.000 0.028 0.000 {method 'lower' of 'str' objects}
663 0.010 0.000 0.016 0.000 {method 'read' of '_io.TextIOWrapper' objects}
1 0.007 0.007 0.007 0.007 {built-in method builtins.sorted}
664 0.004 0.000 0.004 0.000 {built-in method _codecs.utf_8_decode}
663 0.001 0.000 0.872 0.001 __init__.py:608(update)
664 0.001 0.000 0.005 0.000 codecs.py:319(decode)
662 0.001 0.000 0.001 0.000 {built-in method builtins.isinstance}
662 0.000 0.000 0.001 0.000 {built-in method _abc._abc_instancecheck}
662 0.000 0.000 0.000 0.000 {method 'rfind' of 'str' objects}
664 0.000 0.000 0.000 0.000 codecs.py:331(getstate)
662 0.000 0.000 0.001 0.000 abc.py:96(__instancecheck__)
7/1 0.000 0.000 0.000 0.000 {built-in method _abc._abc_subclasscheck}
1 0.000 0.000 0.007 0.007 __init__.py:559(most_common)
1 0.000 0.000 0.000 0.000 __init__.py:540(__init__)
7/1 0.000 0.000 0.000 0.000 abc.py:100(__subclasscheck__)
1 0.000 0.000 1.280 1.280 {built-in method builtins.exec}
7 0.000 0.000 0.000 0.000 _collections_abc.py:392(__subclasshook__)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
1 0.000 0.000 0.000 0.000 {method 'items' of 'dict' objects}
实验发现,将输入当做字节处理与当做字符处理对于性能来说并没有太多的区别。另外,设置 64KB 的块大小是一个经验值,实际上设置任何大于 2KB 的块大小都不会比 64KB 处理起来慢很多。借此也可以看到,许多系统将默认的 buffer 大小设置为 4KB 还是相当合理的。
另外我也尝试过许多其他优化方法,但是以上是使用标准 Python 我所能找到的最佳优化方法。我曾使用 PyPy 优化编译器来执行,但是由于某些原因,执行反而变慢了。在字节码级别对 Python 程序进行优化意义不大,甚至会进一步放慢 Python 的执行速度。按字符处理的程序将在 C 代码中完成。如果您有更好的办法,请告诉我。
Go
一个简单的 Go 实现版本可能是使用 bufio.Scanner 和 ScanWords 代替 split 函数。在 Go 语言中没有类似 Python 中的 collection.Counter ,但是在 Go 中可以使用 map[string]int 数据结构来统计次数,使用其 word-count 切片进行排序:
simple.go
func main() {
scanner := bufio.NewScanner(os.Stdin)
scanner.Split(bufio.ScanWords)
counts := make(map[string]int)
for scanner.Scan() {
word := strings.ToLower(scanner.Text())
counts[word]++
}
if err := scanner.Err(); err != nil {
fmt.Fprintln(os.Stderr, err)
os.Exit(1)
}
var ordered []Count
for word, count := range counts {
ordered = append(ordered, Count{word, count})
}
sort.Slice(ordered, func(i, j int) bool {
return ordered[i].Count > ordered[j].Count
})
for _, count := range ordered {
fmt.Println(string(count.Word), count.Count)
}
}
type Count struct {
Word string
Count int
}
这一版的 Go 语言实现,比简单版本的 Python 实现快很多,但是只比优化版本的 Python 实现快一点点,并且代码行数几乎翻了一番,这也增加了存在错误的可能性。
要使用 Go 的分析器,必须在程序的开头添加几行代码(另外,开头添加 import “runtime/pprof” ):
f, err := os.Create("cpuprofile")
if err != nil {
fmt.Fprintf(os.Stderr, "could not create CPU profile: %v\n", err)
os.Exit(1)
}
if err := pprof.StartCPUProfile(f); err != nil {
fmt.Fprintf(os.Stderr, "could not start CPU profile: %v\n", err)
os.Exit(1)
}
defer pprof.StopCPUProfile()
运行程序后,您可以通过下面命令查看性能分析:
$ go tool pprof -http=:7777 cpuprofile
Serving web UI on http://localhost:7777
Go simple - profiling results
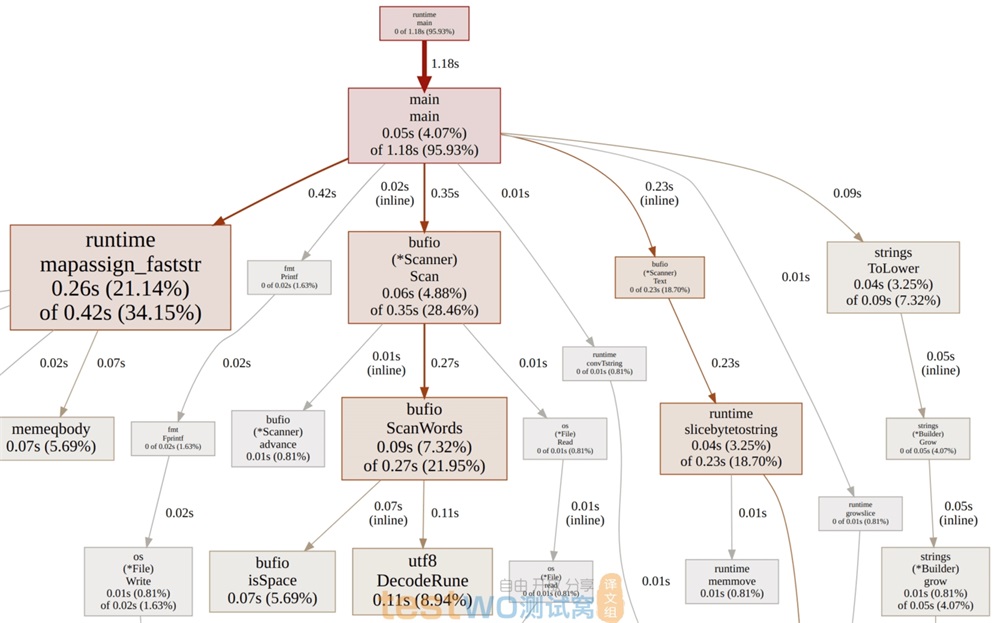
结果很有趣,并不出人意料。对每个单词的扫描计数消耗了大部分时间,另一部分性能消耗严重的地方是在插入 map 时为字符串分配空间,下面我们着重优化这两个部分。
为了提高扫描的性能,我们在扫描单词的同时将其转为小写;为了减少空间分配的性能消耗,我们使用 map[string]*int 代替 map[string]int ,这样就可以仅为唯一的单词分配一次空间,而不是每次增加单词计数时都为字符串分配空间。
上面的优化方法提出并不容易,这是我做了很多实验得到的结果。中间我有实验使用 bufio.Scanner 和自定义的分隔单词函数 scanWordsASCII ,到最后还是发现完全避免 bufio.Scanner 会更快。我还实验了自定义哈希表,但是我认为这对于 Go 的实现版本来说已经超纲了,而且它也并没有比使用 map[string]*int 数据结构快多少。
我最初实现的版本 有时候会发生一些小 BUG :如果读入的部分没有换行符,程序会将最后一个单词从中间分隔然后当做两个不一样的单词去统计。优化的过程是何等容易让人发现一些哭笑不得的语言特性啊! 就像这个 Go 中的 io.Reader 。
不管怎样,它现在已经修复了。感谢 Miguel Angel 注意到这个问题并简化了代码。
optimized.go
func main() {
var word []byte
buf := make([]byte, 64*1024)
counts := make(map[string]*int)
for {
// Read input in 64KB blocks till EOF.
n, err := os.Stdin.Read(buf)
if err != nil && err != io.EOF {
fmt.Fprintln(os.Stderr, err)
os.Exit(1)
}
if n == 0 {
break
}
// Count words in the buffer.
for i := 0; i < n; i++ {
c := buf[i]
// Found a whitespace char, count last word.
if c <= ' ' {
if len(word) > 0 {
increment(counts, word)
word = word[:0] // reset word buffer
}
continue
}
// Convert to ASCII lowercase as we go.
if c >= 'A' && c <= 'Z' {
c = c + ('a' - 'A')
}
// Add non-space char to word buffer.
word = append(word, c)
}
}
// Count last word, if any.
if len(word) > 0 {
increment(counts, word)
}
// Convert to slice of Count, sort by count descending, print.
ordered := make([]Count, 0, len(counts))
for word, count := range counts {
ordered = append(ordered, Count{word, *count})
}
sort.Slice(ordered, func(i, j int) bool {
return ordered[i].Count > ordered[j].Count
})
for _, count := range ordered {
fmt.Println(count.Word, count.Count)
}
}
func increment(counts map[string]*int, word []byte) {
if p, ok := counts[string(word)]; ok {
// Word already in map, increment existing int via pointer.
*p++
return
}
// Word not in map, insert new int.
n := 1
counts[string(word)] = &n
}
性能分析结果看起来更加清晰了:几乎所有时间消耗都集中在主循环中以及 map 操作中。
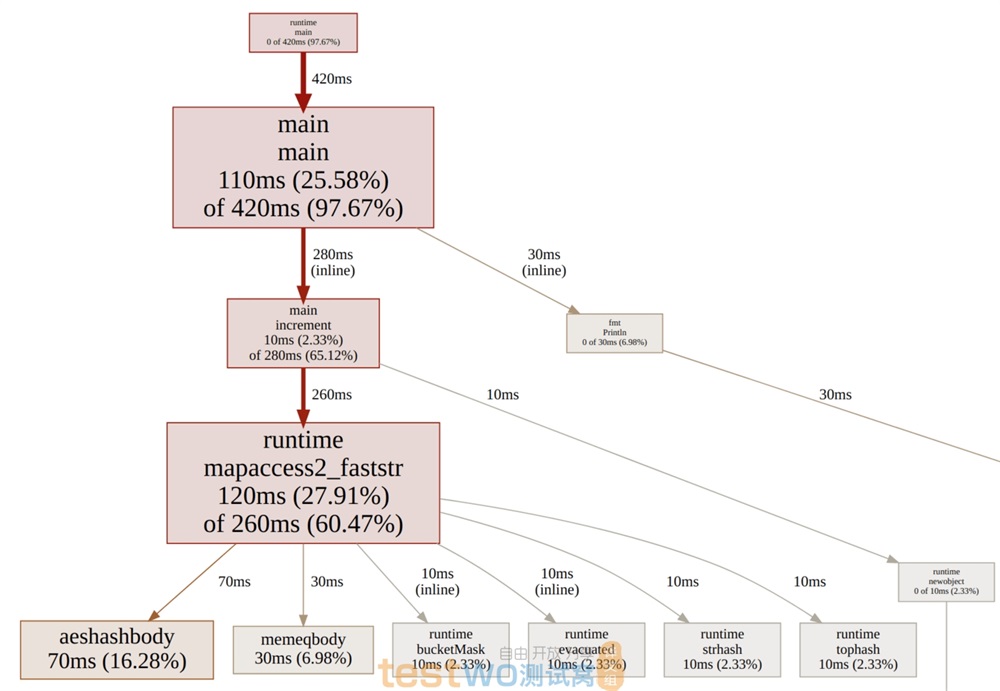
这是一个有趣的练习,Go 提供了相当多的底层控制能力,我们还可以从内存映射 I/O 、自定义哈希表等方面去优化。然而,程序员的时间是宝贵的,所以这是一个权衡。在实践中,我可能还是会使用 bufio.Scanner, ScanWords, bytes.ToLower 和 map[string]*int 技巧的组合。
下篇:一次脚本语言的性能比拼(下)—C++, C, Unix Shell
{测试窝原创译文,译者:lukeaxu}
