

复制
两种解决方案都有不同的复制方法。
在 Mimir 中,每个系列都由分发器复制到摄取器。 如果 Mimir 集群丢失了一个 ingester,则丢失的 ingester 持有的内存序列至少在另一个 ingester 中可用。 因此,当至少有一个副本处于活动状态时,读取查询将成功。 写入查询需要一定数量的副本才能成功,因此复制因子为 3 时,只会丢失一个副本。
当 ingester 返回时,它通过读取 WAL 恢复其内存中状态。 恢复的 ingester 在离线时可能会丢失最近的数据,因此查询器需要查询所有 ingesters 并合并数据以填补空白(如果有)。 每隔 2 小时,每个 Ingester 都会将 TSDB 数据块上传到对象存储,Compactor 会在对象存储中合并这些块,如果有空缺则进行填充,并对数据进行去重,因此长期只存储一个样本。
Mimir 的复制可防止丢失摄取器内存中保存的最新数据,以防计划中的重启或由于硬件问题导致摄取器意外崩溃。 摄取器上的复制无法防止无法访问的对象存储或对象存储上的数据损坏(由于人为错误或压缩错误)。 对象存储数据安全成为存储提供商的责任。
当某些 vmstorage 节点丢失数据时,VictoriaMetrics 的复制可防止数据丢失。 VictoriaMetrics 集群中的 vminsert 将每个传入样本复制到 -replicationFactor 不同的 vmstorage 节点。 例如,如果 -replicationFactor=2,则可以安全地从集群中删除任意 vmstorage 而不会丢失任何数据 - 任意时间范围内的所有查询都会继续返回完整响应。
当一些 vmstorage 节点暂时不可用时,VictoriaMetrics 集群继续接受传入的样本,并根据给定的 -replicationFactor 在剩余的 vmstorage 节点中复制它们。 这意味着当某些 vmstorage 节点不可用时,VictoriaMetrics 不会丢失传入的样本。
VictoriaMetrics 集群通过从剩余的 vmstorage 节点中获取所需的数据来继续为传入的查询提供服务。 如果这种情况下的某些查询依赖于存储在不可用的 vmstorage 节点上的历史数据,则它们可能会返回不完整的结果。 此类查询的响应被标记为不完整。
vmstorage 节点有意没有 WAL,这样它们可以非常快速地启动和运行。
VictoriaMetrics 集群架构允许在不中断数据摄取路径的情况下升级和重新配置集群组件,并且即使禁用了集群级复制,查询路径的中断也最少。 有关详细信息,请参阅这些文档。
虽然在这两种情况下,复制都是关于数据安全的,但它仍然不能保证这一点。 在 Google Cloud 中运行基准测试,使用 SSD 永久磁盘 (SSD PD) 作为本地文件系统,使用 Cloud Storage 作为 Mimir 的对象存储。 SSD PD 具有 5 个九的耐用性,并在引擎盖下使用 x3 复制。 如果假设 Cloud Storage 具有足够高的可用性级别而不会复制它,那么也可以对 SSD PD 进行相同的假设,并在数据可用性方面获得同等水平。 即使云存储比 SSD PD 具有更高的可用性承诺 - Mimir 和 VictoriaMetrics 都将在 SSD PD 失败时面临写入和读取问题,尽管存在复制因素。
复制无法防止因资源不足或工作负载突然增加而导致的内存不足异常 (OOM)。 在 VictoriaMetrics 和 Mimir 中,摄取的时间序列在组件(分别为 vmstorage 和 ingester)之间均匀分片。 因此,如果其中一个组件由于过载而开始出现 OOM,那么其他组件很可能也会出现这种情况。 这种情况可能会由于级联故障而导致数据丢失,其中组件开始一个接一个地崩溃。 只有增加更多的资源或减少工作量才可能有助于摆脱这种情况。
对于 VictoriaMetrics,我建议复制因子为 2,这样可以防止在维护或磁盘故障期间丢失 vmstorage 节点。 如果需要更高的可用性,我们建议将复制卸载到持久的持久性存储(例如 SSD PD)或为集群分配额外的资源。
Mimir 在复制后对数据进行去重的能力非常酷。 它不仅可以降低存储成本,还可以提高读取性能。 VictoriaMetrics 从不删除复制数据的重复项,以保证在某些 vmstorage 节点上的数据丢失时数据仍然可用于查询。
概括
这两种解决方案在处理负载方面都做得很好。没有发生故障或中断,系统在 24 小时的持续写入和读取压力下保持稳定。但是,两种解决方案的不同架构都有其影响。我可以肯定地说,Mimir 比 VictoriaMetrics 更“需要内存”——对于相同的负载,它需要多 5 倍的内存。在进一步扩展工作负载期间,内存是 Mimir 的瓶颈。即使我将摄取器的复制因子从 3 减少到 2,它仍然需要比 VictoriaMetrics 多得多的内存。
虽然没有一个集群达到其 CPU 限制,但 VictoriaMetrics 消耗的 CPU 平均比 Mimir 少 1.7 倍。
Mimir 的第 50 个百分位延迟更好,但第 99 个百分位的延迟是 VictoriaMetrics 的两倍。目前尚不清楚是什么原因导致 Mimir 的延迟出现如此高的峰值。但是,阅读 Grafana Labs 团队进行的文档和其他测试后,我认为 Mimir 可以胜过 VictoriaMetrics,同时在需要扫描已删除重复数据的大时间范围内读取指标
VictoriaMetrics 的磁盘空间使用率较低。如果我们忘记摄取本地文件系统,只将 Mimir 的长期存储与 VictoriaMetrics 磁盘使用情况进行比较——后者仍然使用 3 倍的磁盘空间。虽然对象存储比 SSD PD 便宜得多,但它也意味着数据访问的额外成本。阅读 Mimir 和 VictoriaMetrics 用户关于度量标准存储成本的评论会很有趣。
Mimir 具有巨大的扩展潜力,每个组件都可以轻松扩展。它还具有开箱即用的区域感知复制、对摄取器和查询器的可配置限制、高效的数据存储以及许多其他功能,如查询分片。文档仍然需要一些润色。但总的来说我喜欢这个产品!
在此基准测试中,与 Mimir 相比,VictoriaMetrics 在相同硬件上表现出更高的资源效率和性能。在操作上,VictoriaMetrics 缩放有点复杂,因为数据存储在有状态的 vmstorage 节点上。这使得缩减 vmstorage 节点的数量变得非常重要。我建议始终使用适当数量的 vmstorage 节点来规划集群的体系结构。
在数字上,基准测试结果如下:
●对于相同的工作负载,VictoriaMetrics 使用的 CPU 减少了 1.7 倍;
●VictoriaMetrics 对于相同数量的活动系列使用的 RAM 减少了 5 倍;
●VictoriaMetrics 对基准测试期间收集的 24 小时数据使用的存储空间减少了 3 倍。
奖励:探索极限
在基准测试的奖励回合中,我将只测试 VictoriaMetrics,因为 Mimir 负载的增加开始导致摄取器出现 OOM 异常。自上一个基准测试以来,只有两个参数发生了变化:
# defines the number of node_exporter instances to scrape
targetsCount: 8000
# defines how many pods of writers to deploy.
# each replica will scrape targetsCount targets and will have
# its own extra label `replica` attached to written time series.
writeReplicas: 4
此更改将唯一目标的数量从 6000 增加到 8000,并启动了 4 个 vmagent 副本(每个副本都有唯一标签),这总共增加了 8000 * 4 / 6000 =~ 5 倍的负载。
快速统计
●基准测试已经运行了 3 小时;
●发送给 VictoriaMetrics 的样本总数约为 195 亿:180 万样本/秒 3 3600;
●基准测试期间生成的新时间序列总数约为 3180 万:2750 万个初始序列 + 24K 序列/分钟 60 分钟 3。
结果
基准测试结果是在上一轮基准测试中使用的仪表板快照中捕获的: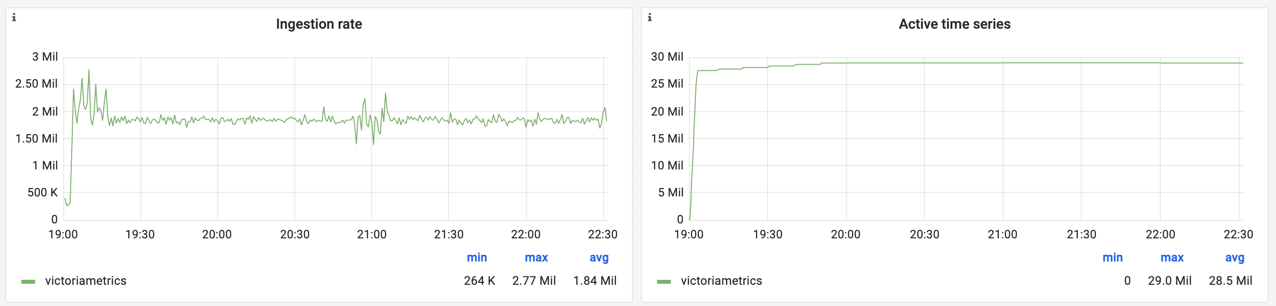
VictoriaMetrics 在基准测试期间保持稳定,成功接收约 180 万个样本/秒和 2900 万个活动时间序列(5800 万包括复制)。 与之前的测试相比,CPU 利用率显着增加:
现在平均使用率达到 32 个可用内核中的 26 个。 如果检查每个 pod 的 CPU 利用率,我们会看到 vmstorages 的平均运行率为 80%,峰值高达 99%。 这意味着进一步扩展需要更多 CPU 用于 vmstorage 节点。
相反,VictoriaMetrics 仅使用允许内存的 1/4: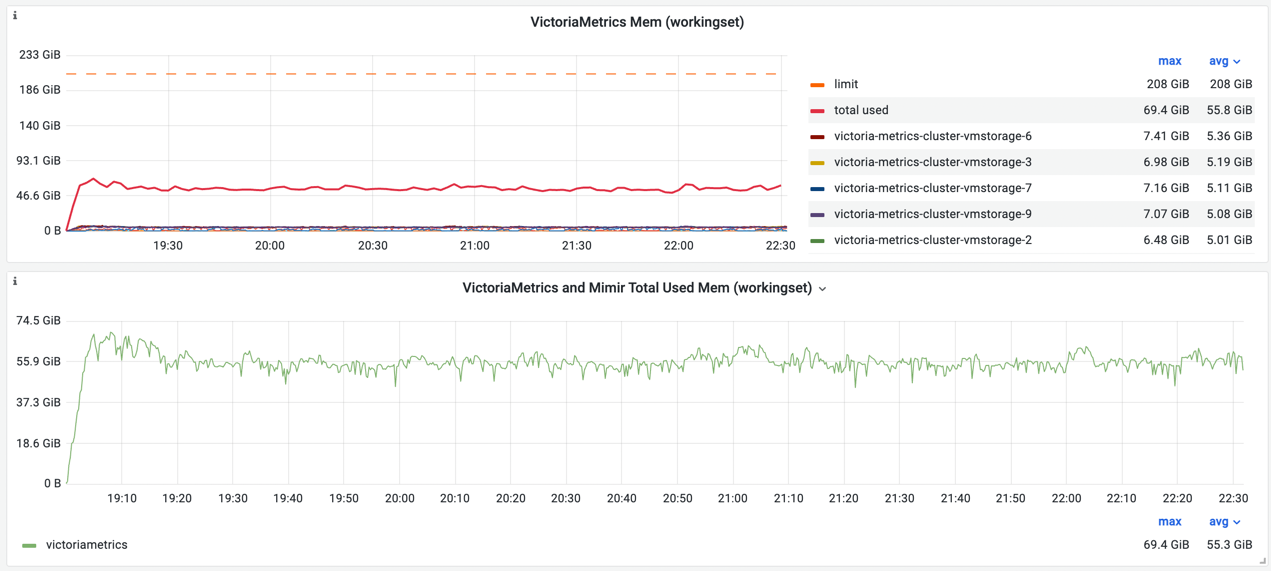
存储节点上内存的平均利用率约为30%。 这意味着,如果摄取率保持不变,活动时间序列的数量可以增加一倍。
随着负载的增加,查询延迟显着降低: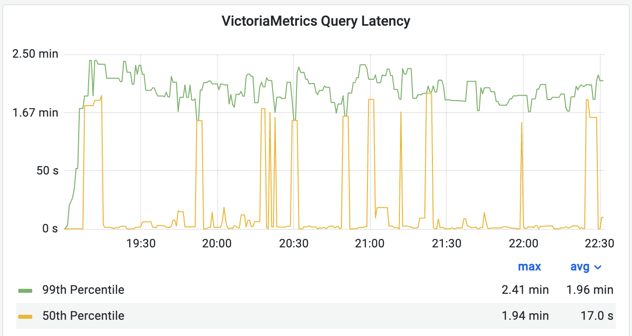
仔细观察会发现 vmselect 之间的平衡不佳。 VictoriaMetrics cluster helm chart 使用标准的 Kubernetes 服务来进行负载均衡,这并没有提供太多的灵活性。 基于这个基准测试的结果,我们计划通过 nginx 使用更好的平衡策略。 类似于在 Mimir 的舵图中完成的方式。
概括
基准文章总是值得阅读的有趣内容。 编写它们的目的是展示不同解决方案的优缺点,以显示令人印象深刻的数字和结论。 然而,我必须提醒一下,没有任何基准是客观的,通常与现实的相关性很弱。 我鼓励读者始终根据自己的特定需求、硬件和数据运行自己的基准测试。 只有这样,才能确定经过测试的解决方案是否符合需求和期望。
