
之前遇到过jbd2引起IO高的问题,直接关掉了日志的功能解决的。写了一个文章,但写的不够细。最近又见类似问题,这里重新整理下对jbd2的内容。
什么原因会导致jbd2引起IO高?
-
磁盘满.
-
系统bug;所知bug号:Bug 39072 - jbd2 writes on disk every few seconds。
-
即使没有以上问题。在ext4上有一个新加入的参数barrier,是用来保证文件系统的完整性的。 [Barrier解释](https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/Documentation/block/barrier.txt?id=09d60c701b64b509f328cac72970eb894f485b9e)。
这个值默认是1,即是打开状态。在这个状态下,打开jbd2也是会导致性能下降的,这个玩意的设计逻辑就是为了损失掉性能保证文件完整性。
这是个选择题,要么不用它,要么性能差。
但是这个功能不能和设备映射器同时使用,也即是,如果你使用了逻辑卷、软RAID、多路径磁盘,则这个值不生效。
jbd2是个什么?
The Journaling Block Device (JBD) provides a filesystem-independent interface for filesystem journaling. ext3, ext4 and OCFS2 are known to use JBD. OCFS2 starting from Linux 2.6.28[1] and ext4 use a fork of JBD called JBD2.[2]
文件系统的日志功能,jbd2是ext4文件系统版本。
检查是否存在jbd2进程

文件系统的日志功能,jbd2是ext4文件系统版本。
检查是否存在jbd2进程

检查文件系统的功能

存在has_journal。
问题现象
在使用iotop看的时候,会有如下信息出现。

解决方案一
关闭日志功能。

如果使用tune2fs时候,提示disk正在mount,如果是非系统盘下,你可以使用

之后在使用上面的命令进行移除has_journal。
解决方案二
如果是bug的话,可以用这种方式解决。如果是不是bug,这种方式也解决不了,所以要先判断下引起问题的原因再选择解决方案。
升级系统内核。

解决方案三
禁用Barrier的同时修改commit的值。这个方式可以解决barrier引起的性能下降,但是解决不了系统bug的问题。
修改commit值,降低文件系统提交次数或者禁用barrier特性; 建议文件系统参数为:

然后重新挂载。

其中barrier=0是禁用barrier特性,commit=60是减少提交次数。 减少提交次数只能缓解。
解决方案四
如果不是bug,并且不想禁用barrier时,用此方式缓解。
想尽办法降低IO,缓解IO压力。这种方式也会导致其他系统资源用不上去。 比如说在mysql中把syncbinlog加大,同时将innodbflushlogattrxcommit增加。 比如说在应用中减少IO的读写。
bug的根源
在之前的版本中出现问题有一个原因是ext4文件系统出现bug。 这个bug出现的比较早了,我看kernel tracker里最早的信息是2011年,如果如果是用的老版本,我建议先做升级。如果没有升级条件,只能用上面的关闭日志功能的解决方案。
bug原因是: 在这段代码中:
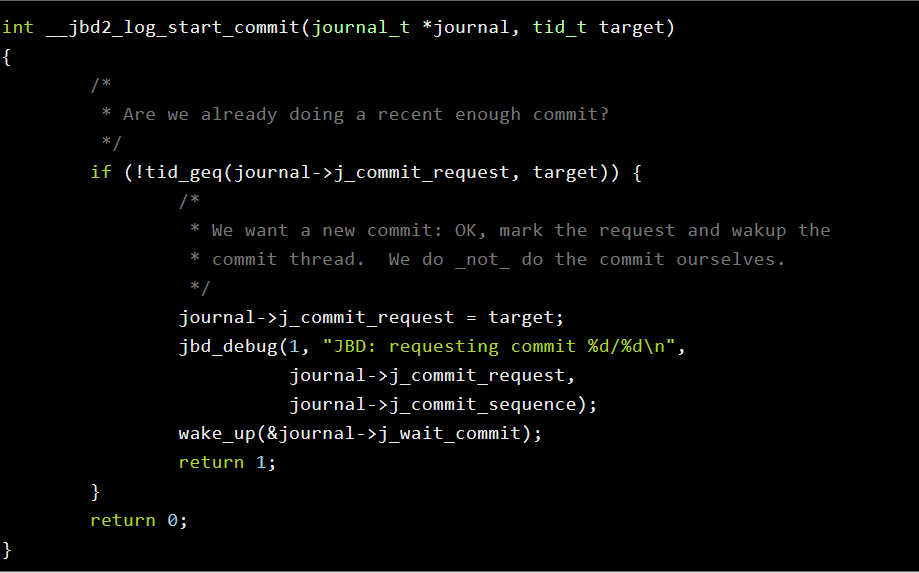
中的tid_geq的函数是这样实现的。
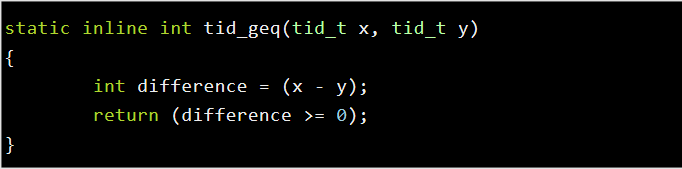
假设jcommitrequest值为2157483647,而target的值为0,看上去 if (!tidgeq(journal->jcommit_request, target))这个判断是不会走的。 但是unsigned int的x减去0之后,转为difference时,difference的定义是int型,此时的结果是多少呢?是-2137483649。 为什么呢?因为unsigned int类型的最大值是2147483647。

而2157483647 - 0的这个结果显然溢出了,变成了负数。比如,你可以尝试这样打印。

结果就变成了:-1。 有兴趣的,可以自己写个简单的源码试一下。
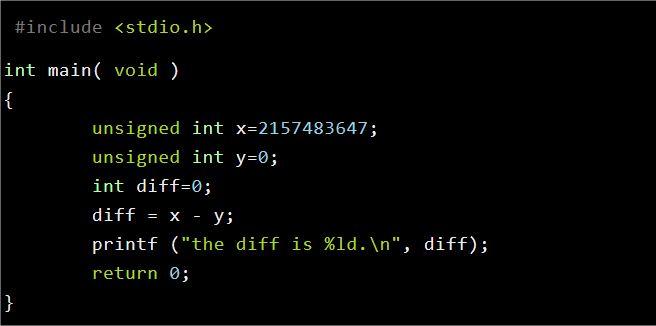
执行之后是什么呢?

可见在这种情况下,因为溢出的变量导致if (!tidgeq(journal->jcommit_request, target))走到了。
这个unsigned int的变量是jbd2给每个transaction的tid,tid是一直增加的,因为这个类型容易溢出,所以用tidgeq来判断下,意思是2157483647这个tid已经提交了,所以把1000号的transaction commit掉,于是执行了wakeup(&journal->jwaitcommit);。但是执行之后才发现,原来并没有运行中的事务,于是系统就疯了。 在trace jbd2的可以看到target有0的情况。实际上,大部分的target都不会是0,这个0是因为ialloc.c中的idatasynctid没有正确赋值,所以使用了默认的0。 idatasynctid是在创建inode或者ext4iget()时更新的,如果应用在打开某些文件后就不再关闭,只是一直更新,这时extent树是不变的(ext4使用extent取代了传统的block映射方式),但是jcommit_request随着jbd2日志的提交而不断增加,所以最后这个差值会在业务运行到一定时间之后出现负值。 如果是这个bug引起的话,可以看到的现象是jbd2这个进程长时间占着99%的IO。
影响版本
有此问题的os版本,只根据我使用过的版本列的:

内核版本:

