
介绍
你是否有这种经历,当你构建了一个新的 Web 应用程序,上线前,老板突然提出几个不那么容易回答的问题:
这个 Web 应用是否可扩展?
能处理 10000 个并发用户吗?
做好成为下一个亚马逊的准备了吗?
还有更糟糕的,当你打开 AWS 的 EC2 实例类型页面,你将看到从 A1 到 z1d 数百种不同的实例类型,如果要成为下一个亚马逊究竟该选择哪一种?
进行负载测试能帮助你组织上面问题的答案。
如何进行负载测试
基础设施设置
负载测试所需的设置,独立于编程语言生态系统(PHP,Ruby,Java等),大致如下所示:
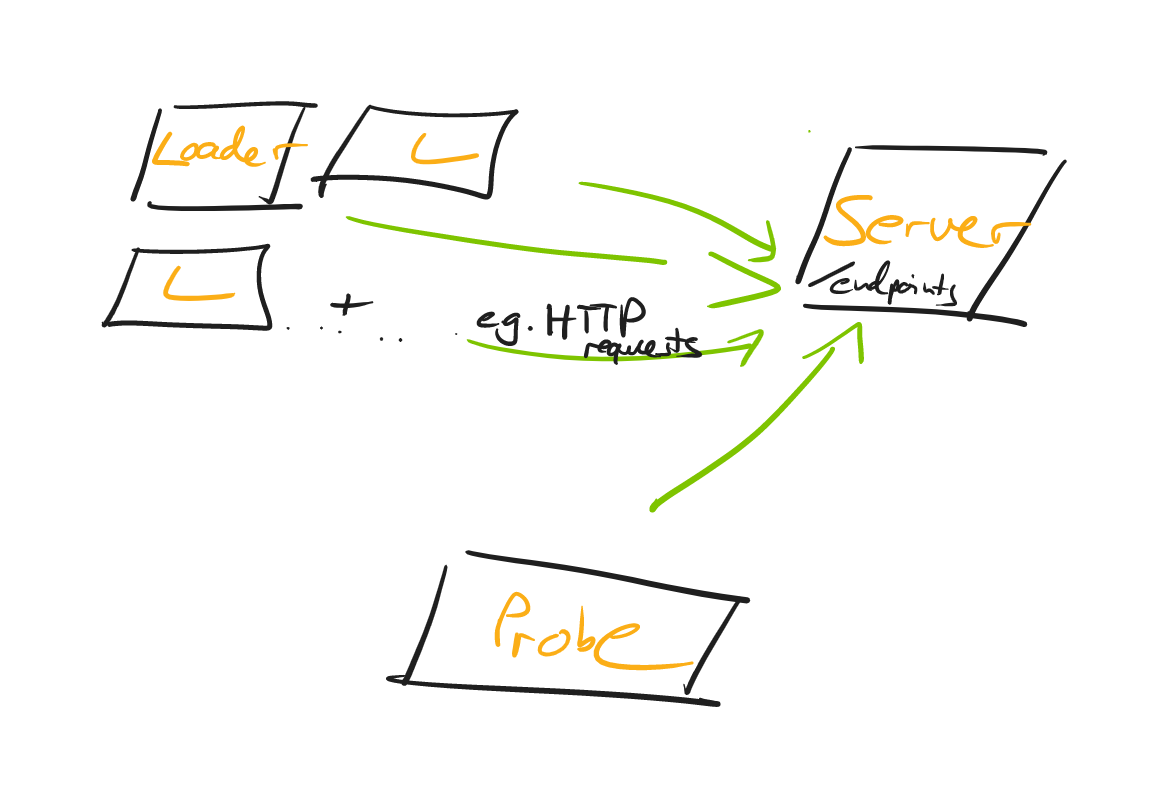
下面仔细看下各部分。
Server
服务器运行被测试的 Web 应用程序,但不一定是单个服务器,实际上,它可以是小型 Web 服务器、Web 服务器与数据库的联合或者整个微服务环境。
Loader
执行测试时,常见的是在运行服务器程序的同一台机器(例如,开发人员的笔记本电脑)上同时运行 Loader 生成负载。
这有什么问题呢?显而易见,生成负载需要占用 CPU/内存/网络流量/IO 资源,这自然会影响测试结果。
因此,这里需要引入一个概念:Loader 是一台能够生成负载的机器,例如能够对服务器发出请求的 HTTP 客户端。
Loader 具有发送 n-RPS(每秒请求数)的能力,n 值的设置将在测试过程中进行调整。您可以从单个 Loader 开始进行负载测试,一旦当前 Loader(s) 难以生成更多负载,则需要增加更多 Loader。
Loader 以恒定速率生成请求也很重要,并且最好异步完成,这样响应处理就不会妨碍发送新请求。
多个 Loader 最好不要共享同一台物理机器的资源,例如相邻的虚拟机可能共享相同的底层硬件。
另外还有一点,可以不必让 Loader 程序记录延迟(例如响应毫秒)。记录延迟的责任我们设计从 Loader 中剥离,转而使用 Probe (探针)来完成。
Probe
Probe (探针)是表示单个用户的机器。
它不会疯狂地生成负载,相反,它缓慢但确定地每秒触发 1-2 次请求,并同时记录响应延迟。
Attention: 关于拆分 Loader (加载程序)和 Probe (探针) 好像颇有争议。如果您有不同的经验,请在评论部分发表评论!
概念
从小处着手
你可能犯的最大错误是一开始便针对整个微服务领域启动负载测试。

因此,明智的方法是:
在测试开始时,先对(分布式)系统的单个单元进行负载测试
单点测试结果表现良好时,就可以使负载测试包含越来越多的服务,直至扩至整个系统
在这个过程中,请注意识别程序负载最薄弱的部分。如果数据库服务在任何给定时间只能处理 3 个 SQL 语句,则无论怎么扩展 Web 服务器都将无济于事。
用户旅程
有一些服务声称自己每秒能处理 1,000,000 个请求,数据很好看,但在进行实际负载测试时对我们并没有什么帮助:除非要构建仅有一个 REST 方法的服务,否则就需要考虑用户正在经历的场景路径和工作流。例如对于电子商务系统来说,将是浏览产品->加入购物车->结帐所包括的所有后端处理。
时长
负载测试应运行多长时间?5秒,42秒还是75秒?1分钟,3分钟还是60分钟?
坦率讲,网上有很多不同的关于测试时长的讨论和建议。你也可以遵从下面的经验来测试:
如果你使用的是 JVM 等平台,则需要在负载测试中包含预热期,该预热期可能介于 20-60 秒之间。在此期间,您不需要记录任何延迟数据等
运行实际负载测试 1-5 分钟
相较于非常具体的测试时长,更重要的是重复运行测试,并检查这些运行的结果。如果你使用几乎相同的参数但获得了完全不同的结果,这时就要对结果进行仔细分析了。
验证测试
记录延迟并不是唯一需要关注的点,你应该验证每个负载测试的运行情况。什么意思呢?验证负载测试需要你找到以下问题的答案:
服务器在 CPU/内存/IO 方面是否过载?
就 CPU/内存/IO 而言,负载生成程序是否过载?
是否有 API 出现问题,返回 400 或 500 状态?
如果你对这些问题中的任何一个回答是肯定的,那么请忽略你的测试结果。
如果服务器是瓶颈,那么您正在极限测试(服务器何时发生故障),而不是负载测试
如果负载程序是瓶颈,则需要扩展更多负载程序。
如果是 API 问题,你可能需要去与开发人员沟通。
这其中最困难的部分是验证每个负载测试都达到一致的标准,或者满足一致的要求,而不仅仅是关注单个的测试结果。
要验证数据,我们需要首先收集数据。我们在下一节中看看具体有哪些数据,如何做到这一点,以及通常希望以什么输出格式查看数据。
负载测试期间要记录的数据
基本负载测试数据
基本的测试数据应该包含延迟、吞吐量和请求状态,下面将逐个进行简单介绍。
这并不意味着您必须立即深入研究复杂的工具,诸如监视解决方案和仪表板工具,相反,您可以从编写几行代码开始,例如记录 REST 客户端的响应时间,并将其转换为 HdrHistogram。
延迟
Probe (探针)将记录每次测试运行的请求-响应时间,然后在开始增加负载后,观察延迟在运行中的变化情况。
为此,不仅要记录原始数据,例如调用应用程序 REST 端点需要:50ms、51ms、37ms、49ms、…,还要在 High Dynamic Range 直方图中可视化这些时间。
下面是一个直方图,显示了探针在多次负载测试运行中的延迟(以微秒为单位,除以 1000 以获得毫秒),其中负载程序的请求从 1000 RPS 升至 50000 RPS。
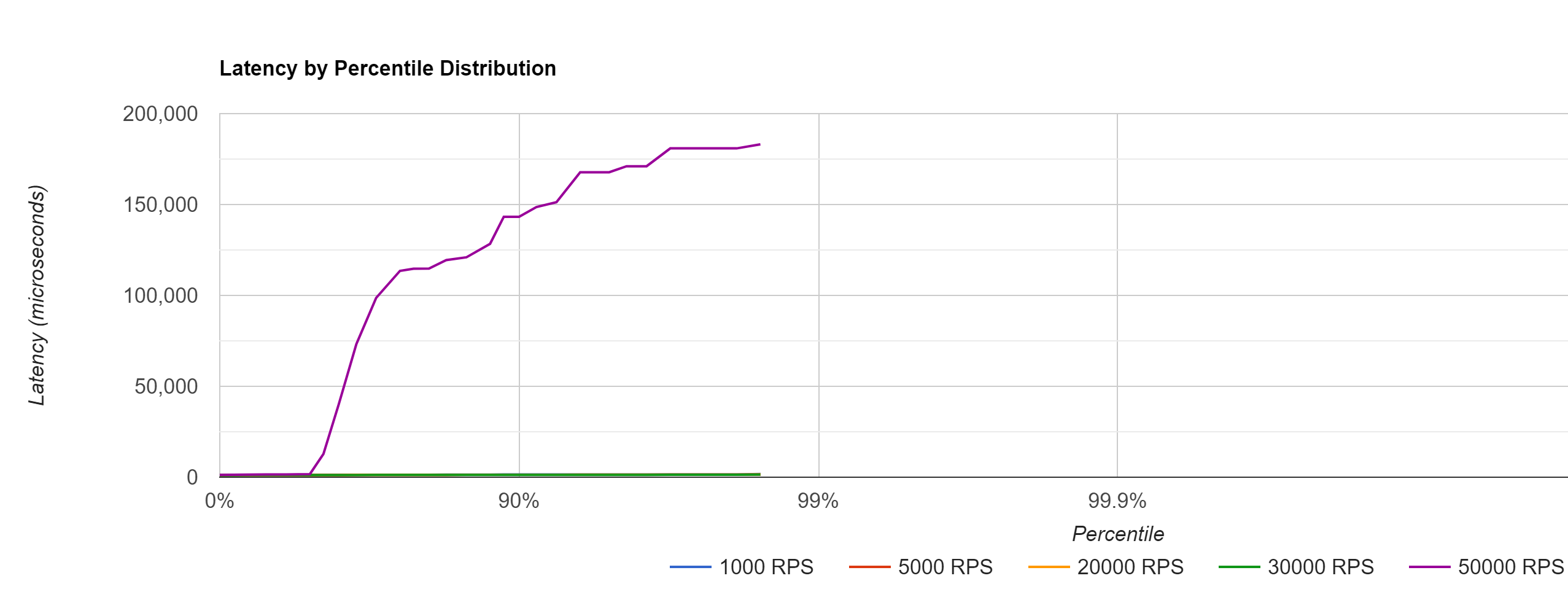
在直方图中,你就可以快速了解响应时间的百分位数,例如 90%、99% 等,以及这些响应时间在不同负载下的变化。
吞吐量
你还需要对负载程序和服务器的吞吐量有一个大致的概述,并再次在折线图中可视化原始数据。
如果你设置加载程序每秒向服务器发送 4000 个请求,吞吐量即每秒发送 4000 个请求。正常情况下,这是一个非常稳定的折线图,如下所示。否则,以为着负载程序生成如此多的请求时遇到问题。
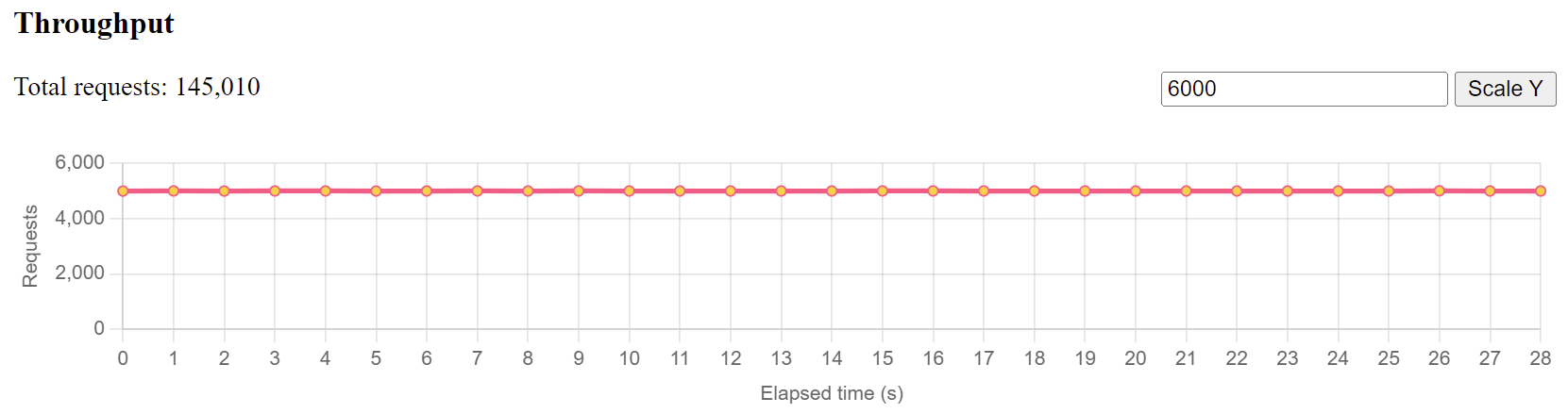
如果您的加载程序运行良好,但您的服务器吞吐量图表如下所示:
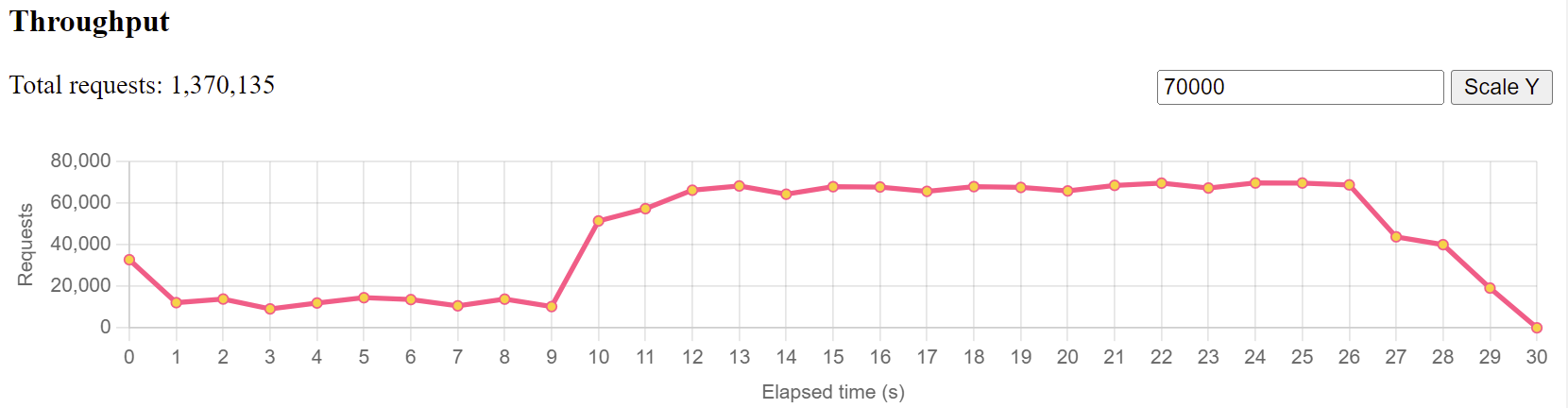
说明你的的服务器在响应这么多请求时遇到了问题,在某一方面肯定达到了极限,你需要检查 CPU/内存/应用程序 数据,以找出根本原因。
HTTP Status Codes
对于负载测试期间发送的每个HTTP请求,都应该记录其 HTTP 响应状态代码。
是否有因为 API 改变而返回 400 的请求?是否有某个 BUG 导致服务器错误而返回 500 状态代码的请求?如果有,你需要丢弃测试结果并重新运行测试。
[0]
252=200
[1]
248=200
[2]
250=200
[3]
251=200
[4]
250=200
[5]
250=200
...
上面是一个自定义文本格式(取自 Jetty Perf 项目),它显示在测试的特定秒内发出的所有 HTTP 请求的状态代码。
就其中一个举例来说:
[0]
252=200
[0]:负载测试的第一秒
252:发送的 HTTP 请求数
200:返回状态代码 200
操作系统指标
若要了解在测试运行期间是否有任何参与者(包括负载程序、服务器、探针)的行为过载,您需要分别记录其操作系统指标。
CPU
如果你使用Linux机器,可以使用 mpstat 命令以特定的间隔(在本例中为5s间隔)在CPU上收集数据。
mpstat -P ALL 5
此命令在具有 4 个 CPU 的计算机上运行 15 秒,获得的输出如下:
08:39:46 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
08:39:46 all 9.15 0.00 7.31 0.01 0.00 1.22 0.00 0.00 0.00 82.31
08:39:46 0 12.64 0.00 8.95 0.00 0.00 0.99 0.00 0.00 0.00 77.42
08:39:46 1 5.25 0.00 3.87 0.00 0.00 5.99 0.00 0.00 0.00 84.90
08:39:46 2 7.70 0.00 6.70 0.00 0.00 0.00 0.00 0.00 0.00 85.60
08:39:46 3 7.77 0.00 6.68 0.00 0.00 0.09 0.00 0.00 0.00 85.46
08:39:56 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
08:39:56 all 7.66 0.00 6.57 0.00 0.00 0.64 0.00 0.00 0.00 85.12
08:39:56 0 11.24 0.00 8.47 0.00 0.00 0.25 0.00 0.00 0.00 80.03
08:39:56 1 4.27 0.00 4.65 0.00 0.00 3.42 0.00 0.00 0.00 87.67
08:39:56 2 5.40 0.00 5.12 0.00 0.00 0.00 0.00 0.00 0.00 89.48
08:39:56 3 9.23 0.00 8.46 0.00 0.00 0.09 0.00 0.00 0.00 82.23
08:40:06 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
08:40:06 all 7.51 0.00 6.12 0.00 0.00 0.71 0.01 0.00 0.00 85.65
08:40:06 0 8.90 0.00 6.32 0.00 0.00 0.27 0.09 0.00 0.00 84.43
08:40:06 1 7.60 0.00 5.65 0.00 0.00 3.00 0.00 0.00 0.00 83.75
08:40:06 2 5.60 0.00 5.60 0.00 0.00 0.00 0.00 0.00 0.00 88.80
08:40:06 3 9.26 0.00 7.95 0.00 0.00 0.09 0.00 0.00 0.00 82.71
上面的每个表对应于所有 CPU(平均值)或单个 CPU(0、1、2、3, 总过 4 个 CPU)的负载快照。
08:39:46 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
08:39:46 all 9.15 0.00 7.31 0.01 0.00 1.22 0.00 0.00 0.00 82.31
08:39:46 0 12.64 0.00 8.95 0.00 0.00 0.99 0.00 0.00 0.00 77.42
08:39:46 1 5.25 0.00 3.87 0.00 0.00 5.99 0.00 0.00 0.00 84.90
08:39:46 2 7.70 0.00 6.70 0.00 0.00 0.00 0.00 0.00 0.00 85.60
08:39:46 3 7.77 0.00 6.68 0.00 0.00 0.09 0.00 0.00 0.00 85.46
你可以用 100 - %idle 来了解你的CPU在该快照期间的平均繁忙程度(例如 100%-82.31% = 17.69%)。
查看单个 CPU 性能的时候,需要特别留意只有一个 CPU 用完,而所有其他 CPU 都处于空闲状态的情况。
Network
根据操作系统不同,你需要使用不同的命令收集网络流量的快照。在 Linux 上,您可以使用 sar 工具每 5 秒收集一次网络流量的快照。
sar -n DEV -n EDEV 5
输出如下所示,其中每两个表对应一个快照。
08:39:36 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
08:39:46 lo 12.30 12.30 1.62 1.62 0.00 0.00 0.00 0.00
08:39:46 ens5 5006.90 5094.00 1208.58 890.41 0.00 0.00 0.00 0.00
08:39:36 IFACE rxerr/s txerr/s coll/s rxdrop/s txdrop/s txcarr/s rxfram/s rxfifo/s txfifo/s
08:39:46 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:39:46 ens5 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:39:46 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
08:39:56 lo 3.70 3.70 0.49 0.49 0.00 0.00 0.00 0.00
08:39:56 ens5 5003.80 5114.30 1207.87 891.30 0.00 0.00 0.00 0.00
08:39:46 IFACE rxerr/s txerr/s coll/s rxdrop/s txdrop/s txcarr/s rxfram/s rxfifo/s txfifo/s
08:39:56 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:39:56 ens5 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:39:56 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
08:40:06 lo 4.00 4.00 0.51 0.51 0.00 0.00 0.00 0.00
08:40:06 ens5 4928.50 5019.20 1189.49 876.60 0.00 0.00 0.00 0.00
08:39:56 IFACE rxerr/s txerr/s coll/s rxdrop/s txdrop/s txcarr/s rxfram/s rxfifo/s txfifo/s
08:40:06 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
08:40:06 ens5 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
重要的是列 rxkB/s 和 txkB/s,如果乘以 0.008,则会将网络接口每秒接收和发送的数据量的单位转换为 Mb。
例如,对于收集的第二次快照:
08:39:46 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
08:39:56 lo 3.70 3.70 0.49 0.49 0.00 0.00 0.00 0.00
08:39:56 ens5 5003.80 5114.30 1207.87 891.30 0.00 0.00 0.00 0.00
接收:1207.87 rxkB/s * 0.008 = 9.66 Megabit
发送:891.30 txkB/s * 0.008 = 7.12 Megabit
Memory
上面提到的 CPU 和网络的所有概念也适用于内存。在 Linux 机器上,您可以使用 free 指令每 5 秒捕获一次内存快照。
free -h -s 5
输出如下所示,每个表对应于一个特定的快照。
total used free shared buff/cache available
Mem: 30Gi 504Mi 29Gi 0.0Ki 519Mi 30Gi
Swap: 0B 0B 0B
total used free shared buff/cache available
Mem: 30Gi 655Mi 29Gi 0.0Ki 519Mi 29Gi
Swap: 0B 0B 0B
total used free shared buff/cache available
Mem: 30Gi 661Mi 29Gi 0.0Ki 519Mi 29Gi
Swap: 0B 0B 0B
输出一目了然,您将从可用的总内存量中看到 free/used 了多少内存。
I/O
将在本文的下一次更新中添加该部分内容。
应用指标
除了系统的全局数据之外,我们还希望能够更深入地了解应用程序内部的情况。为此,需要收集以下数据:
业务逻辑执行时间
这在一定程度上取决于您正在使用的 web 服务器和框架,但本质上,您希望收集的这部分时间不应该包括客户端延迟和无法影响的系统部分。
简而言之:您的业务逻辑需要多少执行时间?例如,Controller 需要多长时间将 SQL 查询结果准备成 JSON 响应内容?
同样,您需要在直方图中可视化数据,以便快速了解测试运行的延迟和百分位数。

火焰图:中央处理器/内存
简单来说,Flame Graphs 允许你可视化应用程序花费其 CPU 和 Memory 的位置。
下面的示例是一个 Java CPU 火焰图,火焰图不仅显示应用程序的代码路径(绿色),还显示 CPU/Memory 在 JVM/C++(黄色)、操作系统(红色)甚至内核(橙色)方面的消耗位置。
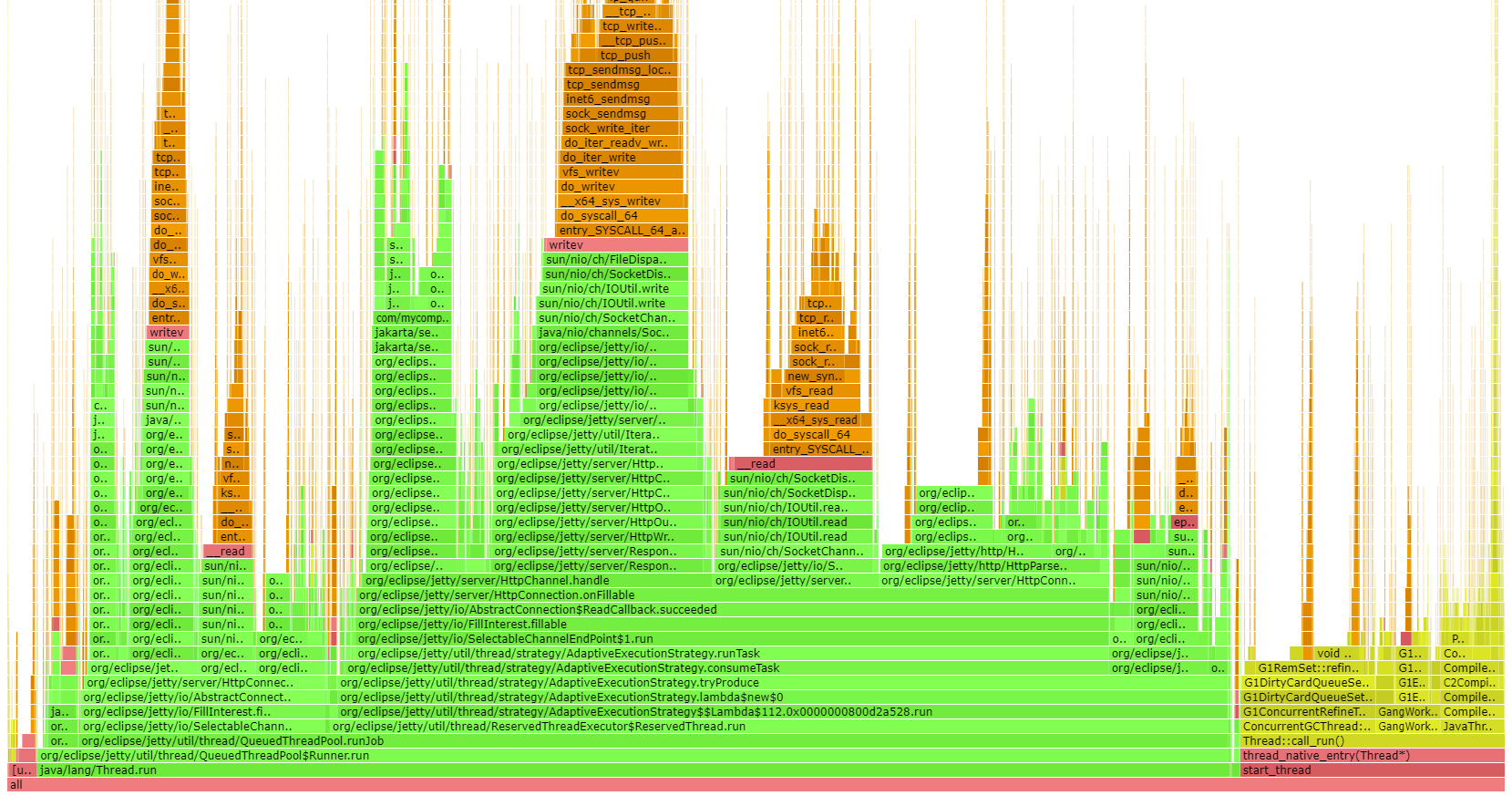
要了解有关火焰图的更多信息,请阅读火焰图发明者布伦丹·格雷格(Brendan Gregg)的页面。
JHiccup/GC(特定于 JVM)
对于像 JVM 这样需要垃圾收集的平台,使用像 jHiccup 这样的检测工具记录垃圾收集日志也是有意义的,工具将记录 JVM 停顿。
如何解释负载测试数据
下面是验证测试运行是否有效时应该遵循的过程。
对于每个测试运行:
检查每个负载测试参与者的全局数据(CPU、内存、I/O)是否存在疑点:这台机器是否接近极限/过载?总体资源消耗趋势如何?
检查特定于应用程序的数据:Hot Code 的执行时间/内存消耗是多少?火焰图和GC呢?可视化结果在测试运行中有何变化?
改变负载,重复运行测试,相应地收集和解释数据。
实际的负载测试
下面是进行负载测试时的一些常见挑战。
绝对数据的诅咒
几乎每个性能图表,或者更确切地说是后续分析,都喜欢关注绝对数据。
但是这些数字,只象征了普通用户工作流程的一小部分,并不意味着什么。如用户旅程中所述,您需要尝试提出现实的用户工作流、场景,尤其是现实的负载,而不是臆造的测试方案。
管理负载测试的期望
许多负载测试方案都基于令人难以置信和不切实际的高负载数。无论是因为一厢情愿的想法(例如,我们下个月将成为下一个亚马逊!),还是过于善意的防备(例如常规照片上传是 4MB,但如果所有用户突然上传 100MB 照片怎么办?),除非有可用的历史数据(或真正充分的理由)表明,例如黑色星期五的抽奖流量是正常流量的 10 倍,否则您的网站或应用程序不会在一夜之间经历指数级增长。
相反,你需要提出现实的数字:很可能在每分钟 XX 请求的范围内,绝对不在每秒 XXXXX 请求的范围内,除非你是支付宝。
极限测试与负载测试
这就引出了最后一点:永远不要与 :load testinglimit testing
到此引出最后一点:不要将负载测试与极限测试混淆:
负载测试:服务器可以处理哪些常规负载而不会经常接近崩溃?
极限测试:让服务器崩溃的”神奇数字”是多少?
要获取什么样实例类型?
对这个问题的一个务实的回答是获得最便宜和”最小”的实例类型:它可以处理您的预期负载,另外还要包括一点缓冲区(我们不希望实例总是以 90% 的 CPU 使用率运行)。
此外,您会惊讶于一个小实例可以处理什么程度的负载。您可以获得更多的实践来收集和解释负载测试数据,因为在选择实例的过程中,您还需要跨不同的实例类型运行负载测试场景!
Further Reading
本文仅仅是一个开始。下面还有一些资源你或许感兴趣:
{测试窝原创译文,译者:lukeaxu}
