自计算机诞生以来,系统性能问题亘古未变,从指令级优化到集成系统的优化,可谓愈来愈复杂。每种类型的性能问题即便出现的场景不尽相同,但依然有一些性能优化模式,久经沙场考验,不断被积累下来。性能问题本质上是一个可观的问题,对于Web App我们更多地可能是谈论与“唯心”相关的问题,最简单的司空见惯的对性能的描述就是,“这系统慢的要死”。接下来,我将以我的经历,谈谈如何对Web App的性能优化亮剑。
1
性能指标
既然,系统需要优化,那么我们必须有一种方法能够量化性能。响应性、响应时间、网络延迟、单位时间内处理的请求数或者是Transaction数量,这几个维度既帮助我们从用户心理角度出发理解性能参数,又可以帮助我们量化性能改进的程度。

基于B/S架构的Web App性能问题,按照前后台任务的不同,一般可以归结为以下几类:前台数据渲染性能问题、后台数据处理时间,包括读取和存入以及Report报表。下面分别来谈一谈。
1.前台数据渲染问题
对于企业级应用系统,尤其是大型企业的应用系统,其数据规模相当可观。至于并发量,其相对于电商类的O2O系统来说,可能显得有点微不足道,但依然存在其本身固有的复杂性。当然,对于渲染海量数据我们有很多种选择,这主要受系统架构的支配和影响。

比如如果采用分页显示,每页只需要显示少量数据即可,用户可通过翻页寻找期望的数据。然而,对于采用OnePage架构风格的系统而言,渲染大量数据就显得没那么简单了。如果终端用户的机器配置不是很高端,那更是雪上加霜。但更加令问题棘手的因素是,对于海量的数据,不仅仅需要展示,而且需要页面逻辑,比如批量更新、页面排序、用户交互等。针对这一性能问题,业界也尝试给出了它们的答案,比如ReactiveJs的出现,使得前台渲染海量数据变得相对简单和成熟了许多。
对于AngularJS,双向绑定、自定Directive、灵活多变的页面处理方式令其一出生就光彩夺目,但是其由于脏检查而又令人深恶痛绝,在渲染海量数据时更是暴露无遗。有一份来自项目上的数据,在单核CPU,、1G内存的机器上,渲染500条、每条平均只有50个字符的数据记录,只要稍微滑动一下鼠标,内存以及CPU的使用率将突增至100%左右。
对于AngularJs的这种诟病,ReactiveJs在诞生之初就考虑到了渲染海量数据的问题。AngularJs虽然本身并没有很好地解决这些问题,但是AugularJS提供给了用户非常灵活的方式,以构建高性能的、基于用户友好的大量数据渲染的解决方案。

前台海量数据渲染问题,归根结底总是只能显示一屏幕数据,即便用户非常贪婪,主观上期望显示出所有满足条件的数据记录,但受制于屏幕大小,永远只能看到一屏幕数据。其实,用户的本质需求是,随着用户输入条件的变化或者是平滑滚动,用户看到的数据会随着用户行为朝着预期的方向进行加载,只是这样而已。因而无论ReactiveJs还是AngularJs,或者其他的JS框架,只要处理好了这个需求,就可以很好地处理前台渲染性能问题。
2.后台数据处理问题
基于MicroService或者Web Service构建的Web App,以及采用RDMS作为存储介质的系统,性能瓶颈可能出现在多个方面,比如网络资源、服务器内存、I/O读写以及多线程CPU资源,这些都与系统本身采用的架构息息相关。

网络资源
网络资源或者是网络带宽性能问题,在这里可能更多地是谈论它的使用效率,最常见的问题包括重复的网络请求、请求处理的跳数多、响应数据量大而臃肿等。
服务器内存
将大量无关数据读入内存做处理,是服务器内存性能问题的主要表现之一。比如搜索功能,所有的与搜索有关的数据和逻辑应该有专门的搜索引擎,而不是简单地将数据读入业务应用层中的内存中实现搜索功能。树型搜索或者Hash比链式搜索,在速度方面占据很大优势。
I/O瓶颈
I/O最常见的性能问题可能就是被大家熟知的N+1问题,它只存在于关系型数据作为存储介质的应用系统中,并且是只有在采用ORM框架的情况下才会出现的特有问题。
3.报表性能问题
数据挖掘或者BI都需要对原始的庞大数据进行特殊处理,数据库模型或者是数据处理的方式是影响报表性能问题的关键因素。报表只是对数据进行读取操作,不涉及到数据更新,这一属性导致报表的数据模型理应与进行业务处理的读写数据模型是不同的。在原始的关系型数据库中,一旦报表的数据模型与业务数据模型一致,就容易出现表级别的数据库连接操作,这无疑会影响整个报表的性能。
2
性能优化的策略与手段
针对单纯的前台数据渲染问题,处理起来相对来说比较简单,一个方案就是静态构建一屏幕数据的DOM结构,动态加载用户数据,无需构建与数据记录等量的DOM元素。后台数据处理的性能问题,处理起来就相对比较棘手,首先受到既定的技术架构的限制,其次在既定的技术架构下,如何合理的划分边界,包括领域模型与API边界,本身就是一个见仁见智很难做出选择的复杂问题。
对于重复的数据请求,处理起来比较简单,只需要去掉冗余的请求即可。如果把对于用户请求的处理逻辑看做服务的话,那么如何设计服务以及定义服务边界就成为了影响性能的关键因素。这背后体现的是用户需求的本质,以及对时间的分片处理。这就要求服务之间关注点各自分离、边界比较清晰,能够适应横向扩展。比如采用Publish-Subscribe模式的系统是一个很好的选择,但是模式永远只是指引的方向,如何很好地应用这些模式,同样需要对业务系统进行不断的探索。
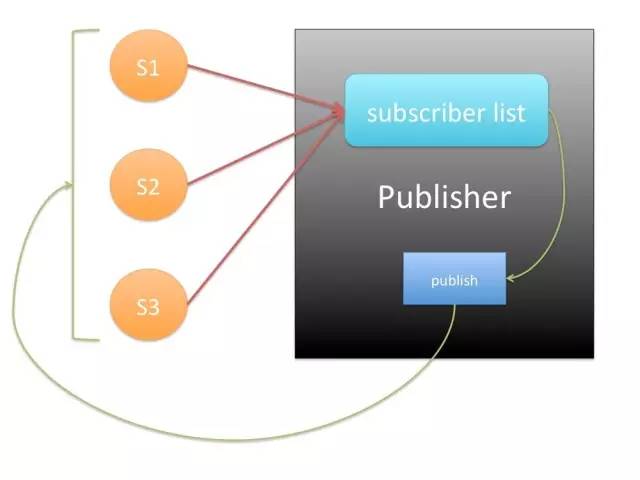
一旦设计了这样的服务,不仅能够灵活支撑扩展性,也使得持续的性能优化成为可能,不仅如此,这样的服务设计,还能够帮我们灵活调整优化策略,比如采用多线程、异步、服务自治、分布式或者集中式节点扩展、灵活选择数据持久化机制等等
处理N+1问题,更多地与业务模型以及业务上下文有关,从DDD的角度考虑这个问题,N+1问题好像不应该存在,这也说明了lazy-load对于DDD而言可能是一个坏味道。但是,解决N+1问题本身也相对比较容易,只要对相应的ORM框架有足够深入的理解以及借用SQL Tuning工具,解决大部分的性能问题。
针对报表的性能问题,仅仅依靠集中式的高性能的单数据库服务器,通过操作表进行数据读取,或者进行连接操作,或者进行映射操作,并不能满足用户对于性能的需求。尤其当有报表中存在业务逻辑时,比如用户权限控制,将使得出报表本身也变的非常复杂。因而,NoSQL以及分片和数据复制可能在这方面有更为出色的表现。
3
性能优化展望

性能问题是一个复杂的领域问题,解决性能问题关键是找出性能瓶颈,但是如果永远只能“东窗事发”之后进行补救还远远不够,因而在解决系统性能的道路上,需要在系统开发时就给予足够的重视,甚至在架构决策时,也应该考虑性能的需求。在今天分布式处理以及大数据技术飞速发展的大背景下,对于性能的解决,我们也许还有更多的选择。
