PS:首先声明,这个标题有点名不符实。哈哈。
不止一次并且在不同的场合都被问到了响应时间该如何分析和定义的问题。问题大概是两种:
-
我们的系统性能差,应该如何分析响应时间呢?
-
响应时间的长短如何定义呢?258原则是否适用?
-
最大值多长算是不可接受呢?
-
不同的系统怎么定最大值呢?
-
我们这个系统是做电商的,应该怎么定最大响应时间、最优响应时间呢?
性能就是这么折磨人,当然这也是它有魅力的地方。
有很多人把性能定义为测试中的一部分,我要说,在一个完整的软件生存周期中,这种只在测试阶段关注性能的,都是太片面了。
要从架构、设计、研发、测试、运维整个周期来看性能,就会发现性能远远不止是测试范围内的,因为任何一个环节的不理智决定都会影响整个系统。
要分析响应时间,先要说明什么是响应时间。
性能测试人员为什么拿着first buffer time、拿着压力工具的响应时间数据曲线来一遍遍问,响应时间长怎么办?
究其细节之后才发现他们根本就不看拆分的响应时间。
不看的大部分原因是不会看。
不会看是不关键的,只是手段不会,而手段是可以查的。
但是性能测试人员有几个又是会去查手段的呢?为什么手段如此难查呢?
不是因为他们不会搜索。
我觉得最大的原因是:没有这个意识!
这和性能测试从业人员整体能力差有关,也和性能这个话题复杂度太大有关。这个复杂度不止是技术上的复杂度,还有沟通上的。
我们先来看一下响应时间的拆分。
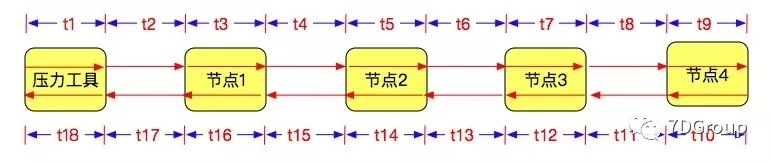
每次在性能分析之前,我都会画一个这样的图,用以整理自己的思路。
性能的标准究其本质就两个字可以概括:快、慢。
在压力工具中,看到的响应时间,把后面一系列(t1-t18)都包含在内了。所以只拿压力工具中的响应时间来讨论是不可能有结论的,所以拆分响应时间才如此重要。
对一个没有全局跟踪id的系统来说,这个时间的查找确实非常费劲,只能通过业务中带的某个ID来一个节点一个节点找下去。
其实能找下去就已经是很好的了。
而对有些系统来说,查响应时间简直就是噩梦般的操作。因为有些日志打印的只有两个字可以形容:恶心!
所以响应时间的长短,不要再只看压力工具上告诉你的了,拆分下去再看如何drill down。
在大部分情况下,我们都不用关心t1/t2/t4/t6/t8/t11/t13/t15/t17/t18,也就是说除了各业务节点上所消耗的时间外,其他地方出现响应时间的问题的可能性比较小。所以在分析响应时间的时候,我们必须列出查找的优先级,那就是:
优先级1:(t9、t10)、(t7、t12)、(t5、t14)、(t3、t16)
优先级2:(t8、t11)、(t6、t13)、(t4、t15)、(t2、t17)
优先级3:(t1、t18)
性能压力工具本身产生的响应问题,非常少。但是也并不是不存在,所以我们放到最后来检查。
上面的优先级为什么要加括号呢?看得明白的肯定是一下就能知道就是为了区分进出两部分。
在这样细分了响应时间后,我觉得不会再有找不到响应时间在哪的问题了。
至于如何操作,在上面玄妙的描述中并没有提及,其原因是,每个节点上用的东西不固定,就无法确定如何操作。
但在一个被分析的应用中,上面节点所使用的东西都是确定的,就可以确定操作了,如果谁有确定的系统,但是又不知道的操作的,要知道人世间还有搜索引擎这样亦正亦邪的事务。
那现在该说说258原则的事情了。
显然,现在大部分人都不再把258原则当成一回事了。
但可悲的是,性能测试人员的第一课就被大部分人教成了响应时间要遵循258原则;就像性能行业中经常有人拿理发店模型来说并发一样可悲。
不能不说,性能测试这个行业发展了十几年(我从业的时间段),到现在为止还有些知识从来未被更新(特别是在意识里)。
在这里,我完完整整的解释下258响应时间,希望能纠正一些视听。
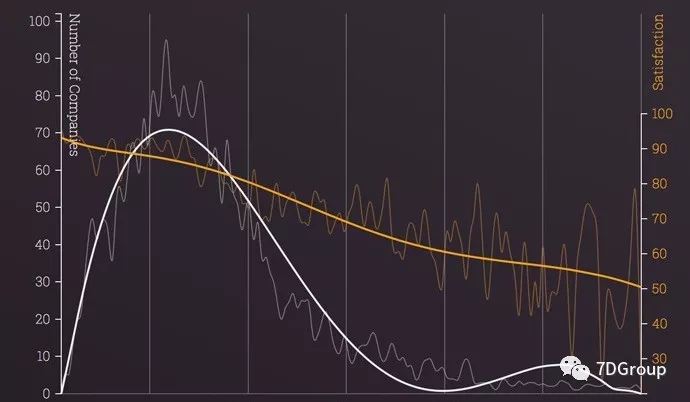
首先,258响应时间是来源于80年代英国的一家媒体针对media做的调查,也就是提供音乐服务的。
在这个调查中,2秒是90%以上的都认为是优质的服务。响应时间越长,满意的人当然就越少。而到了8秒的时候,差不多有50%的人都不满意了。
我记得当时我看到的时候还有一个时间和人员流失率的对比图。
在80年代,你可以想像,那时的服务是个什么标准,我只知道那时我还不记事。
但是那个报告影响了很多事情,以致在国内的性能领域至今还有人当成科普来教新入行的人。
到了90年代,应该是1993年,美国的一家媒体做了另一个针对响应时间的调查,这次是针对零售业,也就是亚马逊、ebay之类的电商服务。这次得出的结论是:
1秒是较好的的响应时间,记住是较好而不是最理想;
0.1秒是最理想的响应时间,因为0.1秒人是无感知的,而1秒会让人感觉到停顿,但是也是可接受的;
4秒是业务可以接受的上限,因为到了4秒的时候,客户流失率明显增加了;
10秒是完全不可接受的,因为已经导致企业的经济已经入不敷出了。
而后出现了很多的技术来让客户觉得页面非常之后,像ajax之类的,当然技术不止是开发技术,在各个不同的领域都在做着努力。
不管是路由、交换、dns设计、负载均衡、高效转发、缓存等等方面,都是在进步的。但是可恶的http协议却一直都没有大变化,每个浏览器的并发请求数依旧是寥寥无几。
所幸的是,其他技术都发展的很快。
而到了2010年的时候,同家媒体又发布了一个报告说,调查了一下,结果和1993年基本上是差不多的。为什么差不多呢?因为是基于人的满意程度( human factors pioneers)来调查的。
也就是说,人还是希望能在无感知的响应时间之内就拿到结果,否则就会不满意(你说说,人类的耐心是不是出奇的差?)。
推而广之,对于实时的业务系统来说,可以说都可以以客户的满意程度做为响应时间的衡量标准。
以上的描述只是针对零售业来的。
对于不同的业务系统,其业务可接受的响应时间当然是不一样的。
所以还是要针对自己的业务系统来做统计量化的工作。
共四步(和大象放冰箱差不多),这里我们仅说响应时间:
-
确定系统功能和使用路径;
-
收集性能目标;(也就是调查客户对响应时间的满意值)
-
量化性能目标(包括分解性能目标、量化各部分性能目标);
-
满足性能目标。
在经过了这些步骤之后,才能让我们明确响应时间这个指标。
看似简单,但是在实际的项目中并不简单。
不简单的是在哪一步呢?就是量化性能目标这一步,记得之前我在一家互联网银行做性能项目时,就响应时间这个指标和很多人开会讨论过。研发经理都希望给自己的系统多留点时间。而越靠近客户的系统就越被动。
所以这个时候,有个职位上的人就应该站出来承担量化分解响应时间的职责,就是架构组(如果架构组是真的干活的话)。
从架构的层面要确定响应时间,我在之前的工作中经常客串这个角色,哈哈,因为一些公司的架构组也确实太架构了。
我之前遇到过一些架构师,吹牛的时候可以说是让人佩服得五体投地,最后解决问题的时候恨不得掐死他。
请大家在以后的工作中不要再拿响应时间要遵循258原则来说事,因为它实在是离我们太遥远了。
其实性能的工作复杂在很多层面,这只是一个层面而已。
人类在进步,科技在发展,知识要更新,可是人生又苦短...呃...我要看书去了。
